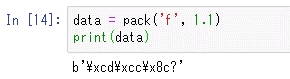前回はテキストファイルを例にファイル操作の基礎を取り上げた。今回はPythonでバイナリファイルを扱う基本について見ていこう。
前回に取り上げた「テキストファイル」とは「文字や数字、記号など、人が読めるものだけで構成されたデータを含んだファイル」といえる(一部、改行コードやタブ文字など、「読める」かどうかは微妙なものもあるが)。第5回「文字列の基本」で述べたように、コンピュータで文字を扱うには、それらに番号を割り振っている。テキストファイルとは、これらの「人が読める文字に割り振られた番号」だけを含んだファイルのことともいえる*1。
*1 実際には、コンピュータが扱える文字の種類を定めた文字セット(文字集合)や、文字セットに含まれる文字をコンピュータ内部で扱えるようにどのようにして番号を割り振るかを定めた符号化方式などに応じて、テキストファイルに文字データを格納する具体的な方式には違いがある(これが「シフトJISのテキストファイル」「UTF-8のテキストファイル」など、テキストファイルにも種類がある理由だ)。
これに対して、「バイナリファイル」とは「テキストファイル以外のファイル」のことだ。音楽データやビデオデータ、プログラムの実行ファイル、プログラムが独自のフォーマットで保存するデータファイルなど、バイナリファイルに保存されるデータは数多い。
とはいえ、今ではさまざまなフォーマットのバイナリファイルをプログラマーが直接扱うことはまずないだろう。そうするためのライブラリが既に多数あるからだ。例えば、本稿では後でGIFファイルを直接オープンして、その画像の横幅や縦幅を調べてみるが、こうした作業を行うためのライブラリとしてPillowがある。ZIPファイルの圧縮/展開を行うなら標準ライブラリのzipfileを使える。このように各種バイナリファイルを扱うための便利なライブラリは多数存在しているが、以下ではバイナリファイルを直接触りながら、その扱い方の基本について見ていこう。
Pythonのプログラムから見たとき、バイナリファイルには「bytes型」で表現されるデータが格納されていると考えられる。テキストファイルとのやりとりでは、文字列(str型)のオブジェクトを渡したり、それが返されたりしたが、バイナリファイルを操作するときにはbytesオブジェクトがプログラムとファイルの間でやりとりされる。
そこでまずbytes型(とその可変バージョンであるbytearray型)について簡単にまとめておこう。
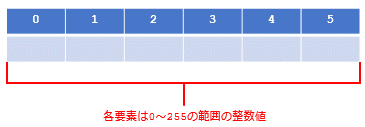
bytes型とは、0~255の範囲の値が連続するデータのことだ。
bytes型のリテラル値は文字列と似た形で表現される。ただし、シングルクオートやダブルクオート、トリプルクオートの前に「bytes型」であることを意味する「b」が前置される点が異なる。以下はその例だ(コメントには実際の値を付記してある)。
value1 = b'a' # 97(ord('a') == 97)
value2 = b'abc' # 97, 98, 99
value3 = b'\x61' # 97(0x61 == 97)
print(value1, value2, value3)
最初の例である「b'a'」は、文字「a」のASCII値である「97」を単一の要素とするbytesオブジェクト(リテラル)である。このように、ASCIIの範囲内にあるアルファベットや数値、記号類を使って、bytes型のリテラルを記述できる。その次の「b'abc'」は、97、98、99という3つの値を要素とする(文字「a」のASCII値が「97」であることは既に説明したので、文字「b」「c」のASCII値も分かるだろう)。最後の例は、文字を使わずに文字列と同様なエスケープシーケンスを使って、「b'a'」と同じ値を持つリテラルを記述したところだ。「\x」というのは次に続く2文字を16進表記の整数値として解釈することを意味する。上の例では「\x61」となっているが、16進数の「61」は「16×6+1」を意味し、結果として10進数表記すれば「97」となる。
実行結果を以下に示す。
上に示した通り、bytes型のリテラル値は人が文字として読める範囲の値については、アルファベットなどを利用して表記されるようになっている。
この他にもbytes関数を使ってもbytesオブジェクトを作成できる。以下に例を示す。
value5 = bytes(10) # 10バイトのbytesオブジェクトを作成(全要素の値がゼロ)
value6 = bytes([97, 98, 99]) # b'abc'を作成
value7 = bytes('abc', 'utf-8') # 文字列'abc'をUTF-8でエンコードしてbytes型に
print(value5, value6, value7)
bytes関数に整数値を1つ渡すと、全ての要素がゼロ(\x00)とし、渡された整数値をそのサイズ(要素数)とするbytesオブジェクトが作成される。上の例なら、10バイトでその要素が全てゼロのbytesオブジェクトが作られる。
また、0~255の範囲の整数値を要素とする反復可能オブジェクト(リストなど)を渡すと、それらを要素とするbytesオブジェクトが作成される。上の例では、97、98、99を要素とするリストを渡しているが、これは「b'abc'」と同じオブジェクトになる。
最後の例は、文字列とそのエンコード方法をbytes関数に渡している。これは渡した文字列を、指定したエンコード方法でエンコードした結果得られる、値の列をbytesオブジェクトの要素とする。Python 3のデフォルトのエンコード方式はUTF-8なので、これは「b'abc'」を作成する。
実行結果を以下に示す。動作を確認してほしい。

文字列と同様、bytesオブジェクトは「変更不可能」である(これに対して、bytearray型は「変更可能」。ただし、本稿ではbytearray型の説明は省略する)。その表記方法も文字列と似ているのは既に見た通りだ。ただし、文字列の要素は文字(デフォルトではUTF-8でエンコードされたUnicode文字)であり、1文字が何バイトになるかはエンコード方式次第となっているのに対して、bytes型の要素は常に1バイト(0~255)となる。
例えば、文字列「'あ'」は1文字だが、UTF-8でエンコードされているとすると、これは実際には「\xe3」「\x81」「\x82」という3バイトの数値で表現される。そして、bytesオブジェクトに「あ」という文字を保存しようとすると、今述べた3つの値が順に保存される。実際に確認してみよう。
文字列をエンコードして、バイト列(bytesオブジェクト)を得るにはencodeメソッドを使用する。引数を指定しなければ、UTF-8形式でエンコードすることを意味する。これを使って、以下のように書けば、文字列「'あ'」に対応するbytesオブジェクトが得られる。
encoded_value = 'あ'.encode()
print(encoded_value)
実行結果を以下に示す。
上述した通り、3つの要素を持つbytesオブジェクトが返されたことが分かる。
一方、bytesオブジェクトを文字列に変換するには、decodeメソッドを使用する。こちらも引数を省略すると、UTF-8形式でエンコードされたものとして、bytesオブジェクトを処理する。
decoded_value = encoded_value.decode()
print(decoded_value)
実行結果を以下に示す。
文字列をプログラムの外部(インターネットなど)とやりとりする際には、今見たencodeメソッドとdecodeメソッドを使って、文字列とバイト列(bytesオブジェクト)に変換することがよくある。
bytesオブジェクトはシーケンスであり、シーケンスが一般にサポートする操作も実行できる(インデックスやスライスによる要素の取り出しなど)。これらについては、Pythonのドキュメント「bytes と bytearray の操作」を参照されたい。
また、変更可能なバイト列を扱う「bytearray型」もあるが、本稿では説明を省略する。
ここまでバイナリファイルを操作する際に使用するbytesオブジェクトについて簡単に見てきた。次に、実際にバイナリファイルを読み書きしてみよう。
バイナリファイルを開くには、テキストファイルと同様、open関数を使用する。以下にその基本的な構文を示す。
open(file, mode='r')
fileにオープンするファイルの名前を、modeにオープンするモードを指定する。modeに指定可能な値は以下の通り。
| パラメーターmodeに指定可能な値 | 説明 |
|---|---|
| 'r' | 読み込み用にオープン(デフォルト値) |
| 'w' | 書き込み用にオープン |
| 'a' | 追記用にオープン |
| 'x' | 排他的書き込み用にオープン(既にファイルがあるときにはエラーとなる) |
| 'b' | バイナリモード(詳細は次回に取り上げる) |
| 't' | テキストモード(デフォルト値) |
| '+' | 更新用にオープン。'r'、'w'、'a'と一緒に指定する必要がある |
| open関数のパラメーターmode | |
バイナリファイルを開くときには、パラメーターmodeに「'b'」を付加する。読み込むのであれば「open(ファイル名, 'rb')」と、書き込むのであれば「open(ファイル名, 'wb')」などとなる。他の値(更新するなら'x'など)については前回の記事を参照されたい。
ここではまず、テキストファイルに文字列「'あ'」を書き込んで、それを今度はバイナリファイルとして開いてみよう。
myfile = open('myfile.txt', 'w') # テキストファイルを書き込み用にオープン
myfile.write('あ') # 文字列「'あ'」を書き込み
myfile.close()
myfile = open('myfile.txt', 'rb') # テキストファイルをバイナリモードで読み込み用にオープン
content = myfile.read()
print(content)
myfile.close()
最初の3行では、「myfile.txt」ファイルを書き込み用にオープンして、それに文字列「'あ'」を書き出して、ファイルをクローズしている。次の4行では、そのファイルを今度は「バイナリファイル」として読み込み用にオープンしている。ファイルからその内容を一括して読み込むのには、テキストファイルと同様にreadメソッドが使える。これにより、文字列「'あ'」が変数contentに読み込まれるので、今度はそれを画面に表示して、ファイルをクローズしている。
実行結果はどうなるだろう。

既に述べたが、文字列「'あ'」をUTF-8でエンコードすると、「\xe3」「\x81」「\x82」という3つのバイトで表現される。テキストファイルとして文字列「'あ'」を書き込むとは、実際にはこの3バイトを書き込むことに他ならない。よって、そのファイルをバイナリファイルとして開いて、中身を読み込めば、その3バイトが今度はbytesオブジェクトとして得られるということだ。変数contentの内容を文字列にデコードすれば、それを文字列として利用できるようになる。
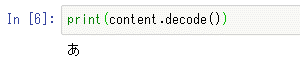
print(content.decode())
実行結果を以下に示す。
もちろん、テキストファイルをテキストファイルとしてオープンして、その内容を読み出せば、それは文字列として扱える(実行結果は省略)。
myfile = open('myfile.txt')
content = myfile.read()
print(content)
myfile.close()
今見たような文字列とbytesオブジェクトとの間の変換処理はWebサーバから得られるHTMLファイルでも同様だ。静的なHTMLファイルでも動的に得られるWebページでも、WebサーバからHTMLをPythonのプログラムで取得すると、通常、それらはbytesオブジェクトになる。そのため、受け取ったHTMLを文字列として扱い、何らかの処理をそれに加えるには、それをデコードして文字列に変換する必要がある。
今度はもう少し難しい例として、GIFファイルを読み込んで、その形式と縦横のサイズを調べてみよう。例としては、前回に掲載した画像を利用する。なお、既に述べているが、画像ファイルを扱うためのライブラリとしてはPillowがある。実際、画像ファイルを読み書きしたいというときには、それらを使うのが簡単でよいことも付記しておく。
この画像ファイルをダウンロードしたら、Jupyter Notebook環境で[File]メニューから[Open]を選択して、ファイル一覧ページを表示する。
ページ右上に[Upload]ボタンがあるので、これをクリックして、ファイル選択ダイアログでダウンロードしたファイルを指定する。
![ダウンロードしたファイルを指定して、[開く]ボタンをクリック](img/BinaryPyope-/di-pybasic3911.gif)
ダウンロードしたGIFファイルのアップロード
これで準備は完了だ。
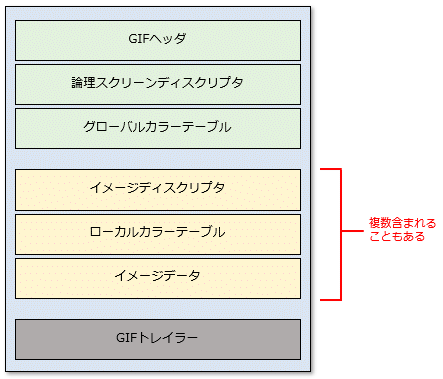
GIFファイルは画像のデータを保存しているバイナリファイルだ。バイナリファイルは多くの場合、その種類によって、データがどのように保存されているかの仕様が定められている。バイナリファイルにデータを保存するときや、逆にデータを読み込むときには、その仕様に従って保存や読み込みを行う。GIFファイルの場合、大まかには次のようになっている(以下は、W3CのGIF89aの仕様書を基に作成)。
先頭のGIFヘッダと論理スクリーンディスクリプタを調べれば、GIFファイルの形式と画面サイズが得られるので、ここではそれ以外は無視する。GIFヘッダは3バイトのシグネチャ「GIF」(16進数表記で「\x47」「\x49」「\x46」)に続けて、同じく3バイトのバージョンが続く。バージョンは「87a」(16進数表記で「\x38」「\x37」「\x61」)または「89a」(16進数表記で「\x38」「\x39」「\x61」)のいずれかだ。これらを合計すると、GIFヘッダは6バイトになる。
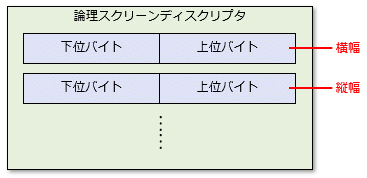
その次に、論理スクリーンディスクリプタがあり、そこに横幅/縦幅の順に2バイトのデータなどが含まれる(他の要素については本稿では省略)。ただし、データが2バイトのときには、その並び順(バイトオーダー)にも注意が必要だ。例えば、バイナリファイルに2進数表記で「0001 0000」、16進数表記で「01 00」という2バイトのデータがあったとき、それが著している値はどう解釈すればよいだろう。
こうしたデータの解釈方法には大きくリトルエンディアンとビッグエンディアンという2つがある。リトルエンディアンというのは、下位バイトから順にデータが並んでいると解釈する方法で、ビッグエンディアンは上位バイトから順にデータが並んでいると解釈する。上の例なら、リトルエンディアンなら下位バイトが先にあるので、「01 00」という並びは実際には「00 01」という16進数と解釈できる。ビッグエンディアンならそのまま「01 00」となる。これらを10進数に直せば、それぞれ「1」と「16」になる。
GIFの仕様では、下位バイトから先に並べることになる(LSB first。リトルエンディアンと同様な意味)。
要するに、GIFファイルの先頭の10バイトを調べると、GIFの仕様と画面サイズが分かるということだ。
では、これをPythonの関数に仕立ててみよう。
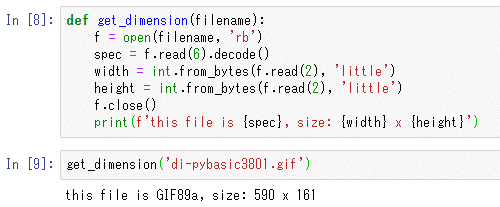
def get_dimension(filename):
f = open(filename, 'rb')
spec = f.read(6).decode()
width = int.from_bytes(f.read(2), 'little')
height = int.from_bytes(f.read(2), 'little')
f.close()
print(f'this file is {spec}, size: {width} x {height}')
まず、指定されたファイルをバイナリモードで読み込み用にオープンする。次に、readメソッドで先頭の6バイトを読み込んで、それをdecodeメソッドで文字列に戻したものを変数specに代入する。バイナリファイルからデータを読み込むと、「GIF」に対応する「\x47」「\x49」「\x46」などの値が得られるので、それらをdecodeメソッドで文字列に変換している。
横幅と縦幅については、int型のクラスメソッドであるfrom_bytesメソッドを使って、readメソッドで読み込んだ2バイトのbytesオブジェクトを整数に変換している。このメソッドの第2引数にはバイトオーダーとして先にも述べたようにリトルエンディアン('little')を指定している。
読み込みが終わったら、ファイルをクローズして、それぞれのデータを保存するだけだ。
実際にこの関数に先ほどの画像ファイルのファイル名を渡してやると、その結果が表示される。
get_dimension('di-pybasic3801.gif')
実行結果を以下に示す。
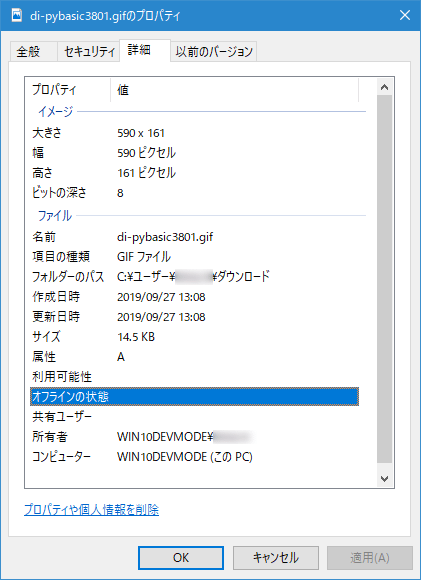
この画像の横幅と縦幅は「590×191」となっている。実際に合っているのが分かるはずだ。
次にバイナリファイルへの書き込みについて見ていこう。
書き込み用にバイナリファイルをオープンするには、open関数のパラメーターmodeに「'w'」や「'x'」と一緒に「'b'」を付加する。注意が必要なのは、テキストファイルではwriteメソッドなどに渡せたのは文字列だけだったのと同様、バイナリファイルではbytesオブジェクトだけということだ。
つまり、次のようなコードを書いてもエラーとなる。
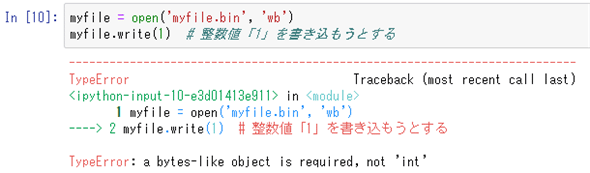
myfile = open('myfile.bin', 'wb')
myfile.write(1) # 整数値「1」を書き込もうとする
これを実行すると、次のようにTypeError例外が発生する。
例外が発生したところで、一度、ファイルをクローズしておこう。
myfile.close()
上の例から分かるように、整数値にしろ、浮動小数点数値にしろ、文字列にしろ、全てのオブジェクトをbytesオブジェクトに変換してから書き込みを行う必要がある。整数(int型)にはto_bytesメソッドがあるので、これを使ってbytesオブジェクトに変換ができる。文字列はencodeメソッドでbytesオブジェクトに変換できる。これらだけなら、変換後のbytesオブジェクトをwriteメソッドで書き込んでやれば問題ない。
だが、浮動小数点数(float型)には同様なメソッドがない。そこで、これらを手軽にファイルに書き込むのに使えるstructモジュールを紹介しよう。
structモジュールにはpack、unpack、calcsizeなどの関数があり、これらを使って整数、浮動小数点数、文字列(をencodeメソッドでエンコードしたもの)をbytesオブジェクトに変換したり、逆にbytesオブジェクトからそれらを取り出したりできる。
bytesオブジェクトへ変換するには、「書式指定文字」と呼ばれる文字を組み合わせて、それらと実際に変換を行う値をpack関数に渡せばよい。このbytesオブジェクトに変換したものをバイナリファイルに書き込むことになる。
逆にバイナリファイルから読み出したデータは、自分でバイナリファイルに書き込んだデータなら、書き込み時に指定した書式指定文字がデータがどのような構成になっているかの仕様となるし、特定のフォーマットのファイルであれば、その仕様から(上のGIFファイルのように)データがどのような並びになっているかが分かるので、そこから書式指定文字が組み上げる。その書式指定文字とデータをunpack関数に渡すことで、バイナリファイルから読み出したbytesオブジェクトから、必要なデータを取り出せる。
書式指定文字には以下のようなものがある(一部。全てはPythonのドキュメント「struct --- バイト列をパックされたバイナリデータとして解釈する」を参照のこと)。
| 書式指定文字 | 説明 | サイズ(バイト数) |
|---|---|---|
| c | 文字 | 1 |
| b | 符号付き整数 | 1 |
| B | 符号なし整数 | 1 |
| h | 符号付き整数 | 2 |
| H | 符号なし整数 | 2 |
| i | 符号付き整数 | 4 |
| I | 符号なし整数 | 4 |
| l | 符号付き整数 | 4 |
| L | 符号なし整数 | 4 |
| f | 浮動小数点数 | 4 |
| d | 浮動小数点数 | 8 |
| s | 文字列 | - |
| < | リトルエンディアンの指定 | - |
| > | ビッグエンディアンの指定 | - |
| structで使用する書式指定文字 | ||
例えば、整数を1バイトの符号付き整数としてbytesオブジェクトに変換するのなら、書式指定文字には「'b'」を指定して、変換したい値と一緒にpack関数に渡す。以下に例を示す。
from struct import pack, unpack, calcsize
data = pack('b', 100)
print(data)
print(f"100 == b'{chr(100)}'")
これを実行すると、次のようになる。
文字「'd'」のASCII値は10進数表記の「100」なので、100をpack関数に渡してbytesオブジェクトに変換すると、「b'd'」となることには注意しよう。逆に得られたbytesオブジェクトを整数に変換するには次のようにする。
result = unpack('b', data)
print(result)
これを実行すると、次のようになる。
結果を見ると分かる通り、得られたデータはタプルに格納されることに注意しよう。ここでは書式指定文字を1文字だけしか使っていなかったので、得られた値も1つだけだが、複数の書式指定文字を指定すれば、それらの数だけデータが得られる。
浮動小数点数についても試してみよう。
data = pack('f', 1.1)
print(data)
これを実行すると次のようになる。
このようにして、pack関数やunpack関数を使うことで、整数や浮動小数点数、文字列などを簡単にbytesオブジェクトに変換できる。
では、実際にstructモジュールを使ってバイナリファイルにデータを書き込んで、それを読み込み直してみよう。
まず、ここではタプルを要素とするリストを作っておく。
mydata = [(1, 'FOO', 1023), (2, 'BAR', 80), (3, 'BAZ', 4000)]
要素となっているタプルには、ID、名前、データが収められているとする。このとき、名前の文字数が同じになっていることにも注意しよう。structモジュールでは(文字数を含めて)このような定型フォーマットのデータを簡単にbytes列に変換できる。ここでは、これらを次のような構成でbytesオブジェクトに置き換えることにする。
これらを書式指定文字で表現すると「l3sll」となる。「s」の前にある「3」は、それが3文字で構成される文字列であることを意味する。
例えば、リストの最初の要素をbytesオブジェクトに変換するのであれば、以下のようになる(文字列が含まれているため、encodeメソッドでbytes型に一度変換しておく必要があり、スッキリとは書けてはいない)。
result = pack('l3sl', mydata[0][0], mydata[0][1].encode(), mydata[0][2])
print(result)
これにより、3つのデータが1つのbytesオブジェクトにパックされる。

要するにこんな感じで、リストの各要素(タプル)をbytesオブジェクトにパックして、それをwriteメソッドでバイナリファイルに書き込んでやればいいということだ。実際のコードは次のようになる。
myfile = open('mydata.data', 'wb')
for item in mydata:
result = pack('l3sl', item[0], item[1].encode(), item[2])
myfile.write(result)
myfile.close()
今度は書き込んだデータを読み込んで、元のデータに復元できるかを確認してみよう。このときには、タプル1つ当たりのデータサイズが必要になる。これを確認するのに使えるのが、calcsize関数だ。これに書式指定文字を渡せば、そのデータのサイズが分かる。
size = calcsize('l3sl')
myfile = open('mydata.data', 'rb')
content = myfile.read(size)
while content:
restored_data = unpack('l3sl', content)
print(restored_data)
content = myfile.read(size)
myfile.close()
ここでは、calcsize関数で調べたデータサイズごとにreadメソッドでファイルから内容を読み込んで、それをunpack関数に渡して、データを取り出して、画面に表示している。それが終わったら、もう一度データサイズだけファイルから読み込みを行い、ファイルが空になるまでそれを続けるようにした。
実行すると、次のようになる。
画像を見ると分かるように、3つのデータを含んだタプルが順次取り出されていることが分かる。また、名前要素はbytesオブジェクトになっているので、実際にそれを利用するのであれば、文字列でデコードする必要があることには注意しよう。
最後に、先ほどのGIFファイルから仕様とサイズを得る関数を、structモジュールを使って書き直してみよう。先ほどの話だと、必要なデータは次のようになる。
これを書式指定文字にすると「6shh」となる。これが分かれば、関数はすぐに書ける。実際のコードは次のようになる。
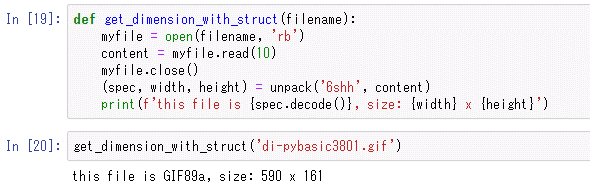
def get_dimension_with_struct(filename):
myfile = open(filename, 'rb')
content = myfile.read(10)
myfile.close()
(spec, width, height) = unpack('6shh', content)
print(f'this file is {spec.decode()}, size: {width} x {height}')
ここでは先頭の10バイトを最初に読み込んでしまって、それを上述の書式指定文字と一緒にunpack関数に渡している(バイトオーダーを指定していないので、環境によっては間違った値に変換されるかもしれない)。
unpack関数はbytesオブジェクト化されている「GIF+仕様」と、横幅、縦幅をタプルにまとめて返すので、これを3つの変数spec、width、heightに代入するようにしている。後は、それらを画面に表示するだけだ。
実際に実行した結果を以下に示す。
こちらのコードでは、int.from_bytesメソッド呼び出しを書かずとも自動的にbytesオブジェクトから整数値を取り出せるなど、元のコードと比べて、若干簡単にはなっているはずだ。このように、自分がバイナリファイルに書き込んだデータでなくとも、仕様を基に自分で書式指定文字を組み立てることで、外部ファイルを読み込んで、そのパースを行うのにもstructモジュールは使える。
structモジュールを使うと、このように比較的簡単に定型データをbytesオブジェクトに変換して、それをバイナリファイルに書き込んだり、バイナリファイルから読み込んだりできる。しかし、特定のフォーマットを持つデータを読み書きするには、pickleモジュールなどより便利なモジュールも用意されている。これらについては次回紹介しよう。
今回はバイナリファイルからのデータの読み込みと、structモジュールを使ったバイナリファイルへのデータの書き込み(と読み込み)について見た。次回はpickleモジュールなど、「オブジェクトのシリアライズ(直列化)」を行うモジュールについて見ていこう。
Copyright© Digital Advantage Corp. All Rights Reserved.





![[Upload]ボタンをクリック](img/BinaryPyope-/di-pybasic3910.gif)
![画像ファイルの横にある[Upload]ボタンをクリックする](img/BinaryPyope-/di-pybasic3912.gif)