サンプルアプリケーションの概要
サンプルアプリケーションでは、図1に示すようなバックエンドでのデータ管理と郵便番号から住所データを提供するような簡単なアプリケーションです。今回は、バックエンドでのデータ管理について説明します。
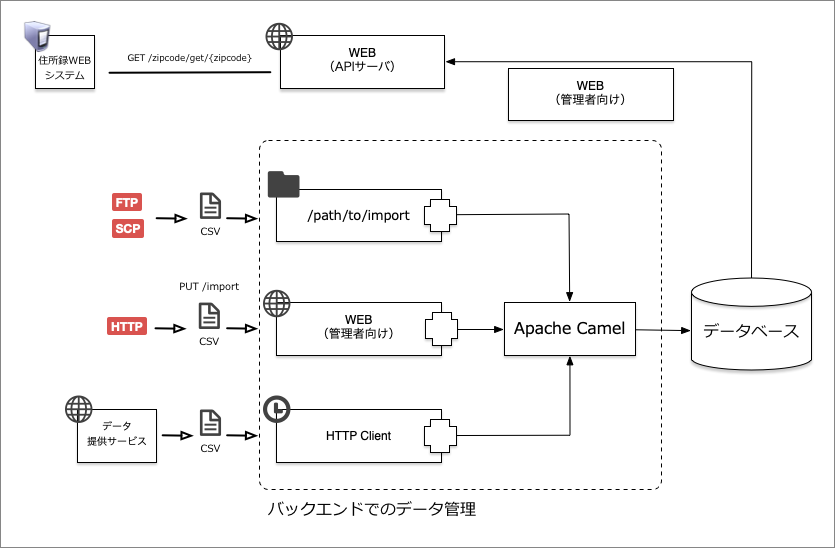
このアプリケーションでは、表1のデータ登録方法を提供します。
| 手法 | 概要 |
|---|---|
| ファイルアップロード | HTTPでのファイルアップロードからデータを取り込む機能 |
| データ受信 | FTPやSCPなど指定したフォルダ内のファイルを取り込む機能 |
| データ取得 | 外部WEBサイトからデータを取得し自動で取り込む機能 |
Apache Camel
今回のサンプルアプリケーションはApache Camelを使ってデータ処理を行っています。
Apache Camelは図1のように、さまざまなデータの入出力を行うコンポーネントを組み合わせることで、開発者がデータ操作に集中できるフレームワークです。
用意されている入出力コンポーネントはApache Camelのサイトの通り、非常に多くあるのがわかります。自分で独自の入出力コンポーネントを作成することもでき、特殊な入出力に対応することも可能です。
こういったフレームワークはEIP(Enterprise Integration Patterns)フレームワークと呼ばれていて、同様なフレームワークにはSpring Integrationがあります。EIPフレームワークという言葉に慣れていなくても、EAI(Enterprise Application Integration)製品という言葉なら知っている方もいると思います。
EIPフレームワークはEAI製品が行っている処理と同様のことができます。また、一部のEAI商用製品では内部のシステムとしてApache Camelを使っているケースなどもあります。

Spring BootでのApache Camelの利用
Spring BootでApache Camelを使うとき、Gradleの場合には、リスト1のように「org.apache.camel:camel-spring-boot-starter」というスターターを追加します。
dependencies { : // (省略) implementation 'org.apache.camel:camel-spring-boot-starter:2.24.1' }
処理ルールの記述方法
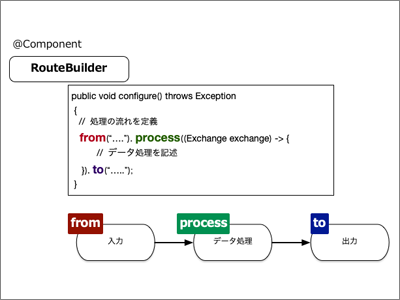
Apache Camelの処理ルールは、図3のようにRouteBuilderクラスを継承したクラスをBean登録すると自動的に動作するようになります。
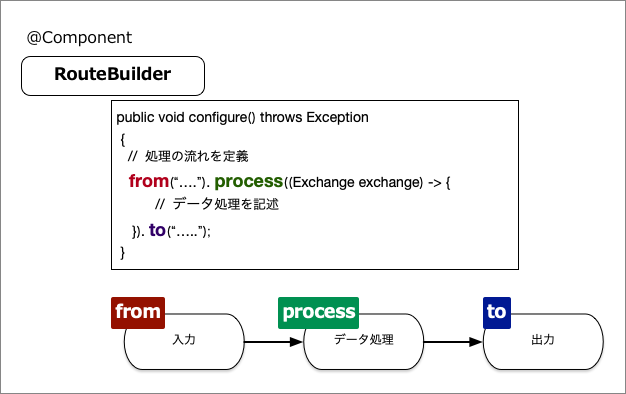
実際の処理内容の説明は後述しますが、処理ルールはリスト2のような流れで記述します。
import org.apache.camel.builder.RouteBuilder; : (省略) @Component public class ZipcodeImportRouteBuilder extends RouteBuilder { // (1) 定義を宣言する設定 @Override public void configure() throws Exception { // (2) 処理ルートを定義する from("file://" + file.getAbsolutePath() + File.pathSeparator + "import").process(new Processor() { @Override public void process(Exchange exchange) throws Exception { // ファイルが存在したときの処理を記述 } }).to("direct:import"); // (3) ルートは複数指定できる from("direct:import").process(new Processor() { // (省略) }); } }
(1)のconfigureメソッド内に処理の流れを宣言します。(2)と(3)のように複数の処理の流れを宣言することも可能です。from()メソッドはデータの入力元を示し、process()メソッド内でデータ処理を記述します。最後のtoで出力先を指定します。(2)の出力を(3)での入力として利用しています。これらの流れを図にすると、図4になります。
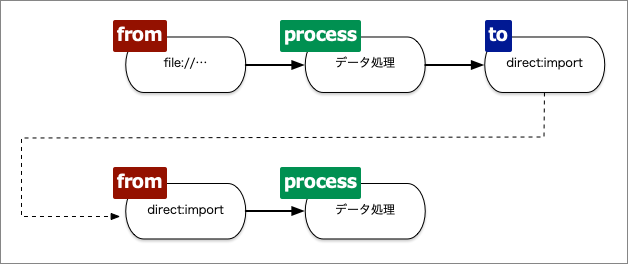
ルート定義の方法には、ここで紹介した以外にもデータの分岐やフィルタ処理など、多彩な記述が行えます。また、Java以外のXML等など記述方法もいろいろあるので、詳しくはApache Camelの利用マニュアルを見てください。
バックエンドでのデータ管理
Apache Camelのおおよその流れがわかったところで、実際のデータを登録する処理を説明します。また、今回は利用する郵便番号データは、今回は日本郵便のHPからダウンロードしたものを利用しました。
[Note]日本郵便のHPからダウンロードできるデータについて
日本郵便のHPからダウンロードできる郵便番号データは、自由に利用できますが、その場合には多少の注意が必要です。データ内の住所項目を見ると、「次のビルを除く」や、「以下に掲載がない場合」、複数の丁目「(1~3丁目)」や「(その他)」などのデータがあるので、これらのデータを実際に利用できる形に修正する必要があります。
また、今回のサンプルのダウンロードURLに直接、日本郵便のHPのダウンロードURLを指定しないようにお願いします。
サンプルのアプリケーションとコードの関係を示したものが図5になります。
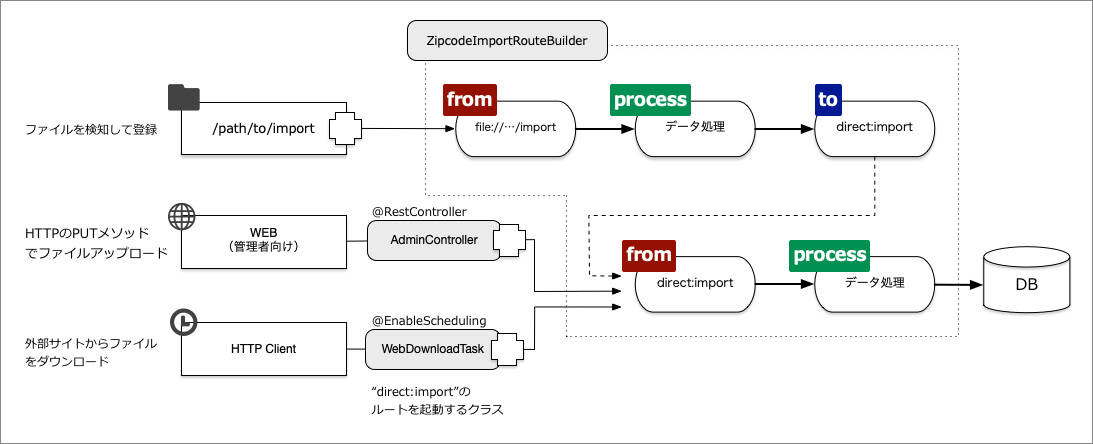
また、データ管理を行っているクラスは表2の機能が実装されています。
| クラス名 | 概要 |
|---|---|
| ZipcodeImportRouteBuilder | Apache Camelのルート定義をするクラス |
| WebDownloadTask | Springのスケジュール機能を利用した定期ファイル取得処理 |
| AdminController | ファイルアップロードを受け付けるRest API処理 |
フォルダを利用したデータ登録・更新
指定したフォルダにファイルが存在すれば、そのファイルを検知し自動的に郵便番号データとしてデータベースに登録する流れにします。その処理のサンプルコードがリスト3です。
この処理は、FTPやSCPなどによってデータが送信されてきて、指定のフォルダにアップロードが終わったタイミングで処理が実行されることを期待しています。
@Component public class ZipcodeImportRouteBuilder extends RouteBuilder { : (省略) @Override public void configure() throws Exception { File file = new File("."); // (1) 実行しているフォルダ以下のimportフォルダをチェックする from("file://" + file.getAbsolutePath() + File.pathSeparator + "import").process((Exchange exchange) -> { File importFile = exchange.getIn().getBody(File.class); InputStream is = new FileInputStream(importFile); // (2) 次処理の入力データを設定する Message in = exchange.getIn(); in.setBody(is); }).to("direct:import"); // (3) InputStreamの入力を受けてデータを登録するルート from("direct:import").process((Exchange exchange) -> { Message msg = exchange.getIn(); Object body = msg.getBody(); if(body instanceof InputStream){ InputStream is = (InputStream)body; try { importData(is); exchange.getOut().setHeader("Status","OK"); } // (省略) } }); } // (3) protected void importData(InputStream is) throws UnsupportedEncodingException, IOException{ // (省略) InputStreamからCSVデータを読んで、DBに追加、または更新する } }
(1)の"file://..."というエンドポイントのURI内に検知する際のフォルダを指定します。指定したフォルダにファイルが存在すれば自動で処理が実行されます。
(2)では、次の処理の入力データとしてInputStreamのインスタンスを設定しています。入力時のオブジェクト型は自由なので、データを受ける処理側で型を意識する必要があります。
(3)の"direct:<任意の名前>"というエンドポイントは、何も処理が行われないまま、次の処理に進みます。この名前を使って他の処理から自由にこの処理を呼び出すことができます。また、(3)は実際のCSVデータを読み取り、データベースに登録する処理です。実際のコードは添付するサンプルコードを参照してください。
定期スケジュールでデータを取得する
続いて、定期的なスケジュールで外部のWebサイトにあるデータを取得し、データベースに登録・更新する処理を想定します。定期的なスケジュールや、外部のWebサイトからデータを取得することもApache Camelで記述が行えますが、今回はSpringでのスケジュール機能を利用します。
Spring Bootでスケジュール機能を利用する場合には、リスト4のように@EnableSchedulingアノテーションを宣言する必要があります。
import org.springframework.scheduling.annotation.EnableScheduling; @EnableScheduling public class MainApplication { // (省略) }
また、スケジュールとして実行される処理は@Scheduledアノテーションをメソッドに宣言し処理を記述します。
リスト5は、Springのスケジュール機能を利用し、Apache Camelのルート処理を実行する際のサンプルコードです。
: (省略) import org.springframework.scheduling.annotation.Scheduled; import org.springframework.stereotype.Component; @Component public class WebDownloadTask { // (1) Apache CamelのContextオブジェクトを取得する @Autowired CamelContext camelContext; // (2) Springのスケジュール機能を使った実行 @Scheduled(cron = "0 0 1 * * *") public void downloadFile(){ // (3) 指定したURLからファイルをダウンロードする HttpClient client = HttpClient.newHttpClient(); HttpRequest request = HttpRequest.newBuilder(URI.create(downloadUrl)).build(); try { Path path = Files.createTempFile("download-",".zip"); HttpResponse<Path> response = client.send(request, HttpResponse.BodyHandlers.ofFile(path)); File file = path.toFile(); if(file.exists()){ ZipFile zipFile = new ZipFile(file); ZipEntry entry = zipFile.entries().nextElement(); InputStream is = zipFile.getInputStream(entry); // (4) ダウンロードしたZipファイル内のデータ(1つのみ)を入力とし、"direct:import"のエンドポイントに処理をつなげる ProducerTemplate template = camelContext.createProducerTemplate(); Exchange exchange = template.send("direct:import", (Exchange obj) -> { obj.getIn().setBody(is,InputStream.class); }); // (5) 処理結果を取得する Message out = exchange.getOut(); String status = out.getHeader("status",String.class); if(status.equals("OK")){ log.info("import OK"); } // (省略) } } // (省略) } }
(1)では、Apache CamelのContextオブジェクトを取得します。Apache Camelの外から処理を実行する場合にはこのオブジェクトを取得します。また、このオブジェクトはSpring Boot側で自動的に作成されています。
(2)では実行するスケジュール処理を記述しています。また、サンプルではスケジュールはcron形式での記述が可能であり、ここでは毎月1日の00:00に処理を実行するように指定しています。今回使用したcron表記方法以外にも表3の表記方法があり、cron以外の表記方法はTimerクラスを使ったスケジュール実行と同じルールになります。
(3)では指定したURLからファイルをダウンロードしています。ダウンロードするファイルはZip圧縮されている前提としています。続いて、(4)では(3)で取得したデータを利用し、Apache Camel側で作成した"direct:import"というエンドポイントに入力を渡します。
このようにApache Camelの"direct"というスキームは、外部のプログラムからも実行できるので非常に便利です。
処理の結果を取得したい場合には、(5)のようにして結果を取得することもできます。
| クラス名 | 概要 |
|---|---|
| cron | cronでの記述方法と同じように記述可能 |
| fixedDelay | 前の処理と次の処理の間隔が指定したミリ秒になるように処理が実行される |
| fixedRate | 指定したミリ秒間隔で処理が定期的に実行される。処理開始の間隔になるので処理自体が長い場合には、同時に2つ以上の処理が実行される場合がある |
| initialDelay | 最初の処理を行うための待機時間 |
HTTPを使った、ファイルのアップロード処理からのデータ登録
HTTPのPUTを使ったファイルアップロードを使ってデータを登録する場合では、これまでの例と前回までのRestControllerの知識があれば実装可能です。
詳しい説明は割愛しますが、リスト5のコードで実装できます。
@RequestMapping("/admin/zipcode") public class AdminController { // PUTでのファイルアップロード処理 // curlを使ったファイルアップロード例 : curl -u -X PUT http://127.0.0.1:8082/admin/zipcode/import -T import.csv @PutMapping("/import") public Response importAction(InputStream is){ // 受信したデータを使ってApache Camelのルートを実行する ProducerTemplate template = camelContext.createProducerTemplate(); Exchange exchange = template.send("direct:import", (Exchange obj) -> { obj.getIn().setBody(is,InputStream.class); }); // (省略) } }
最後に
Spring Bootを使う理由の1つとして、TomcatなどのWebコンテナとSpring Frameworkという使い方だけではなく、今回のサンプルアプリケーションのように、Webだけではない別のフレームワークとWebフレームワークを混在させた1つのアプリケーションが作りやすい点があげられます。
また、Webシステムだけであれば、PHPやRuby、Pythonといったスクリプト系の言語の方が使いやすい場合がありますが、今回のようなHTTP以外での入出力データをカバーする必要が生じた場合にJavaという言語の強みがより一層引き立つはずです。
次回は、今回作成したサンプルアプリケーションに認証をつける方法や、細かなSpring Bootの設定カスタマイズなどを紹介します。