初めてのJPA--シンプルで使いやすい、Java EEのデータ永続化機能の基本を学ぶ
Java EEアプリケーションにおけるデータベース操作を、よりシンプルで簡単にするためのデータ永続化機能が「JPA(Java Persistence API)」だ。同APIのキホンを、書籍「わかりやすいJava」シリーズでおなじみの川場隆氏が解説する。
Java EE 6や同7など最新のJava EEを使用したアプリケーション開発に初めて取り組む方にとって課題の1つとなるのは、Java EE特有のデータ永続化機構である「JPA(Java Persistence API)」の習得であろう。入門者向けのJava解説書として定評のある「わかりやすいJava」シリーズで知られる川場隆氏(活水女子大学 教授)の解説により、JPAの基本を学んでいただきたい。
※本記事は、日本オラクルが2015年4月に開催した「Java Day Tokyo 2015」における川場隆氏のセッション「やさしく理解するはじめてのJPA」の内容を基に構成しています。
JPAとは何か?

活水女子大学 教授の川場隆氏
この記事では、JPAを初めて学ぶ方に対して、同APIを使う際に必要となる基本的な事項を解説します。
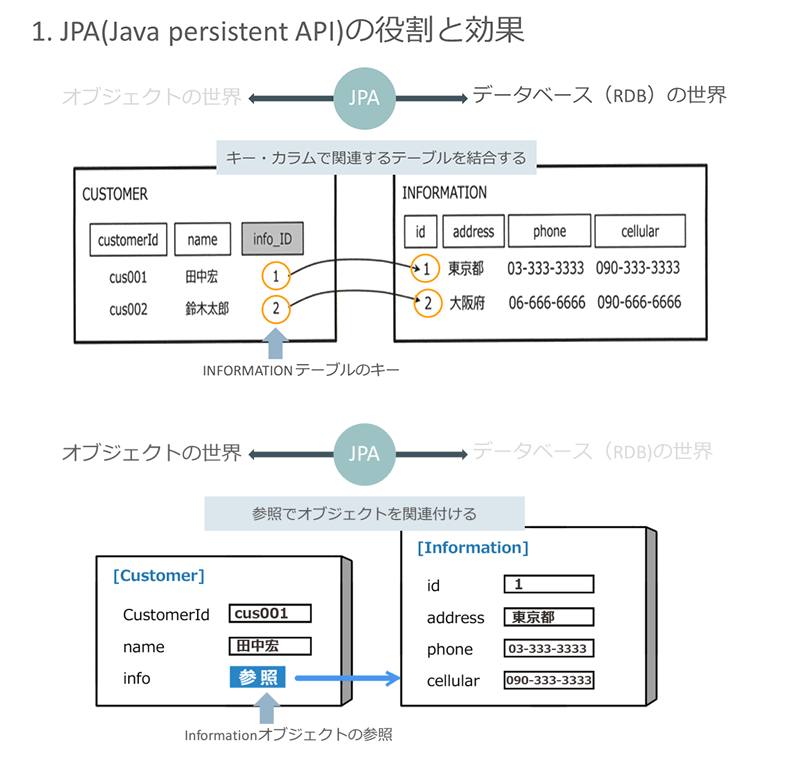
まずは「JPAとは何なのか」ということから始めましょう。端的に言えば、JPAとはJavaの世界とリレーショナル・データベース(RDB)の世界を直接的に結ぶための仕組みです。「JavaのオブジェクトとRDB(レコード、テーブル)との間で自動変換を行う仕組み」がJPAだと理解していただけばよいでしょう。
下図に示すように、Javaの世界では「参照」によってオブジェクト間を結び付け、RDBの世界では「キー・カラム」によってデータベース・テーブルの間を結び付けています。
※クリックすると拡大画像が見られます
この「参照」と「キー・カラム」による関連付けの間を相互変換することで、JavaオブジェクトとRDBの間の関連付けを行うのがJPAの役割なのです。
JPAの主な特徴を列挙すると、次のようになります。
- Javaオブジェクトとデータベース・テーブルとの間の変換指定(マッピング指定)をアノテーションだけで行える
- Javaオブジェクトを、そのまま読み書き/削除/検索することができる
- オブジェクト指向の問い合わせ言語(JPQL:Java Persistence Query Language)を利用できる
- JPQLと同等のAPIも使うことができる
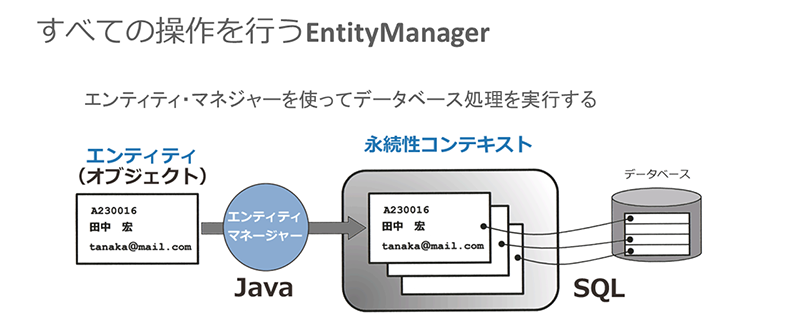
JPAの仕組みは非常にシンプルであり、次の3つの要素から成ります。
- エンティティ:データベースに保管するオブジェクト。つまり、データベース・レコードに相当するオブジェクト
- エンティティ・マネジャー(EntityManager):エンティティを管理するオブジェクト
- 永続性コンテキスト:EntityManagerの配下にあり、エンティティの状態を表すオブジェクト
この3つの要素の中でも、中心的な役割を担うのがEntityManagerです。EntityManagerがエンティティを受け取り、さまざまなデータベース処理を一括して実行するのです。
※クリックすると拡大画像が見られます
エンティティの作り方
JPAでは、エンティティを表すクラス(エンティティ・クラス)の作成も簡単に行えます。普通のJavaクラスを作り、それに@Entityというアノテーションを書くだけでよいのです。これだけで、作成したクラスを「データベースに書き込む1件のレコード(つまり、エンティティ)」として定義することができます。
【リスト1:エンティティ・クラスの例】
import java.io.Serializable; import javax.persistence.*; import javax.validation.constraints.NotNull; @Entity public class Employee implements Serializable { @Id @NotNull // Null禁止。ビーン・バリデーションも指定できる private Integer number; // 社員番号 private String name; // 氏名 private String mail; // メール public Employee(){} // 実用上はインスタンスを生成するためのコンストラクタも作っておく public Employee(Integer number, String name, String mail){ …略… } // setter/getterメソッド。NetBeansなどのIDEを使うと自動生成できる }
このほか、リスト1からもわかるように、エンティティ・クラスの作成に当たっては次のような簡単な決まり事があります。
- 主キーの項目に@Idを付ける
- publicで引数のないコンストラクタを持たせる
- 必ずカプセル化を行う(setter/getterメソッドを用意する)
- クラスやフィールドにfinal修飾子を付ける
ちなみに、Java対応統合開発環境の「NetBeans」を使うと、setter/getterメソッドのコードが自動的に生成されるので便利です。
EntityManagerの基本メソッド
EntityManagerは、パッケージjavax.persistenceのインタフェースであり、主なメソッドとして次が用意されています。
【表1:インタフェースEntityManagerで宣言されているメソッド】
| メソッド | 機能 |
|---|---|
| void persist(Object e) | エンティティeをデータベースに新規登録する |
| E merge(E e) | データベース中のエンティティを引数に指定されたエンティティeで更新する |
| void remove(Object e) | エンティティeを(データベースから)削除する |
| E find(E.class, Object key) | key(主キー)で検索して見つけたエンティティを返す |
| E getReference(E.class, Object key) | findと同様だが、遅延フェッチを行う |
| void refresh(Object e) | 永続性コンテキストにあるエンティティeを、データベースから取得した値で更新する |
| void clear() | 永続性コンテキストをクリアし、エンティティを永続性コンテキストから分離する |
| void flush() | 永続性コンテキストにあるエンティティを即時にデータベースと同期する |
| void detach(Object e) | 引数のエンティティを、永続性コンテキストから分離する |
| boolean contains(Object e) | 引数に指定されたエンティティが永続性コンテキストの中にあるかどうかを調べる |
最初は、表中の「persist(新規登録)」、「merge(更新)」、「remove(削除)」、「find(検索)」という4つのメソッドを覚えておけばよいでしょう。
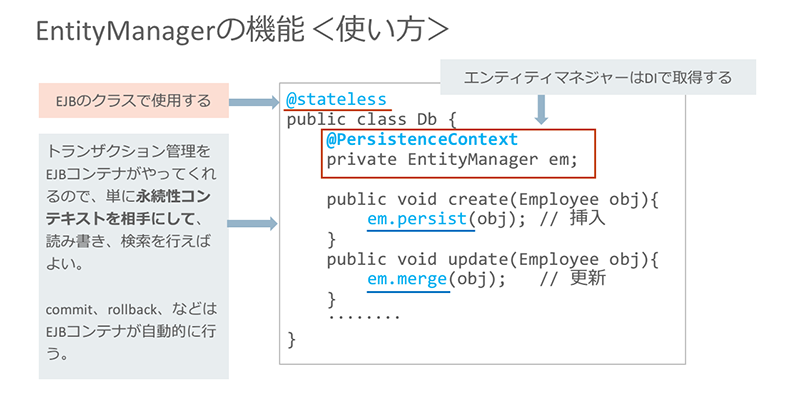
それでは、これらのメソッドはどこに書くのでしょうか。答えは簡単、EJBクラスに定義すればよいのです。
※クリックすると拡大画像が見られます
Java EEでは、普通のクラスに@statelessというアノテーションを付けると、そのクラスがEJBコンテナの管理対象となり、データベースとのトランザクション制御などが自動的に行われます。なお、上の図中で下線を引いたメソッドpersist、mergeの引数に指定している「obj」がエンティティ・オブジェクトです。
また、EntityManagerオブジェクトは、DI(Dependency Injection:依存性の注入)によって取得します。つまり、@PersistenceContextというアノテーションにより、EJBクラスの変数に対してEntityManagerオブジェクトへの参照を注入できるわけです。後は永続性コンテキストに対し、前掲のEntityManagerのメソッドによって実行したいエンティティの操作を指定します。
このように、EntityManagerの使い方はとても簡単ですが、エンティティごとにEJBクラスが必要となるため、複数のエンティティを使う場合には作成に手間がかかります。これを避けるには、下図の要領でどのような型のエンティティでも処理することのできる"総称型のスーパークラス"を使うとよいでしょう。

※クリックすると拡大画像が見られます

※クリックすると拡大画像が見られます
これにより、エンティティごとのEJBクラスのコーディングを次のように簡素化することができます。

※クリックすると拡大画像が見られます
エンティティごとに、上図のように6行のコードから成るクラス、つまりCreate(生成)、Read(読み取り)、Update(更新)、Delete(削除)のCRUD処理を行うEJBクラスを作ればよいわけです。
ただし、検索系のメソッドでは、エンティティの型情報が必要となるので、総称型スーパークラスのコンストラクタの引数で型情報を取得できるようにしておきます。

※クリックすると拡大画像が見られます
「永続化」の意味
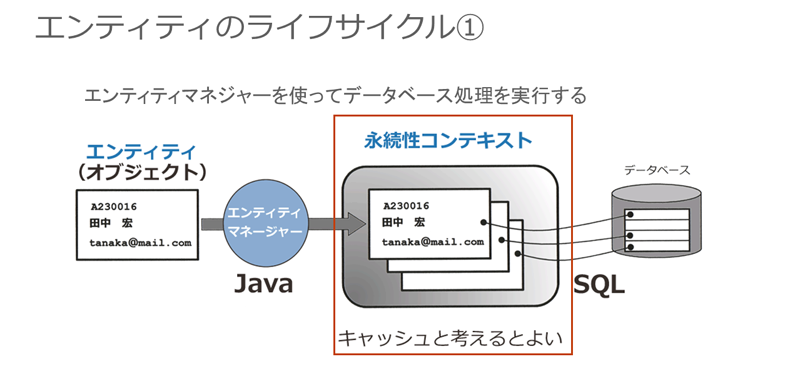
EntityManagerのメソッドで操作したエンティティは、いったんEntityManagerの永続性コンテキストに配置されます。例えば、メソッドcreateでエンティティに対する「新規登録」の操作を行っても、その時点ではデータベースへの書き込みは行われません。実際には、「このエンティティは、データベースに新規登録するデータである」というマークを付けて永続性コンテキストに配置されるだけです。これがオブジェクトの「永続化」であり、EntityManagerによってデータベースへの格納が可能になった状態であることを意味しているのです。
※クリックすると拡大画像が見られます
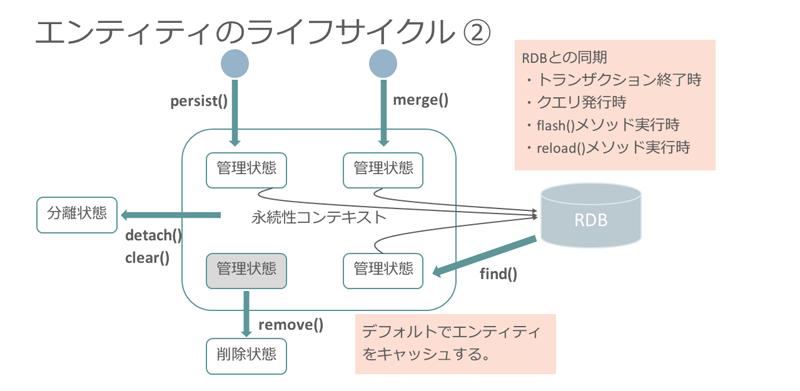
※クリックすると拡大画像が見られます
JSFとの親和性が高いJPA
JPAはJava EEの一部であることから、Java EEの他のAPIと容易に組み合わせて使えるよう工夫されています。例えば、JSF(JavaServer Faces)を使用すると、JPAの扱いがとても簡単になります。
JSFでは、WebアプリケーションのWeb層とビジネス・ロジック層の間でデータ管理を行うBacking Beanクラスを、@Namedと@RequestScopedという2つのアノテーションを付けて作ります。このクラスを使うことで、Webフォームのフィールド項目とプログラムの変数をバインドすることができます。
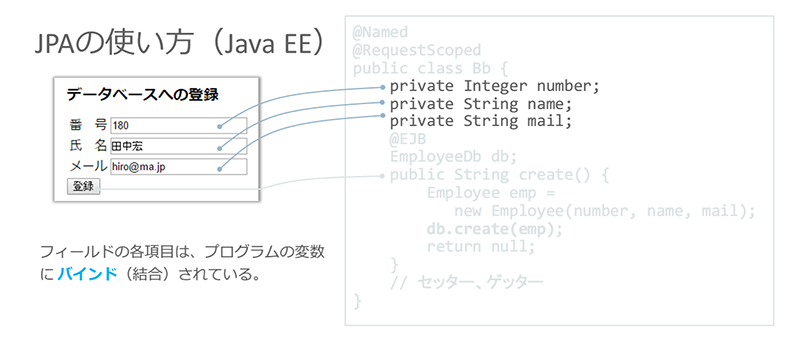
※クリックすると拡大画像が見られます
また、JSFではWebページ内のボタンがクリックされた際に実行するメソッドを指定できます。そのため、例えば「登録」ボタンがクリックされたら、EJBクラスのメソッドcreateを実行するといったことが行えます。
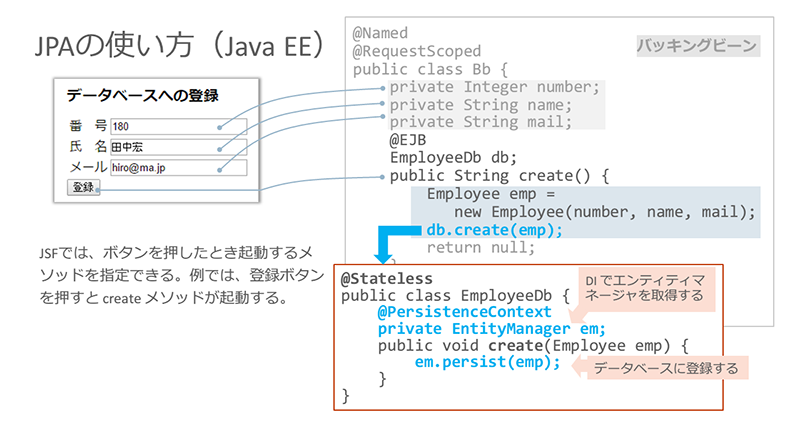
※クリックすると拡大画像が見られます
ちなみに、上図に示したBacking Beanのメソッドcreateでは、Webフォームから受け取ったデータを基にしてエンティティ(Employeeエンティティのempオブジェクト)を生成し、「db.create」によってデータベースに登録するという処理を行います。この「db」が、EJBクラスであるEmployeeDbのオブジェクトです。
エンティティとデータベース・テーブルのマッピング
JPAでは、エンティティとデータベース・テーブルをどのように対応づける(マッピングする)かについて、その大枠が標準で決められています。
例えば、「エンティティ・クラス名」は「テーブル名」にマッピングされ、エンティティ・クラスの「フィールド変数名」はテーブルの「カラム名」に対応づけられます。そして、@Idアノテーションにより、フィールド変数が主キーに変換されるといった具合です。
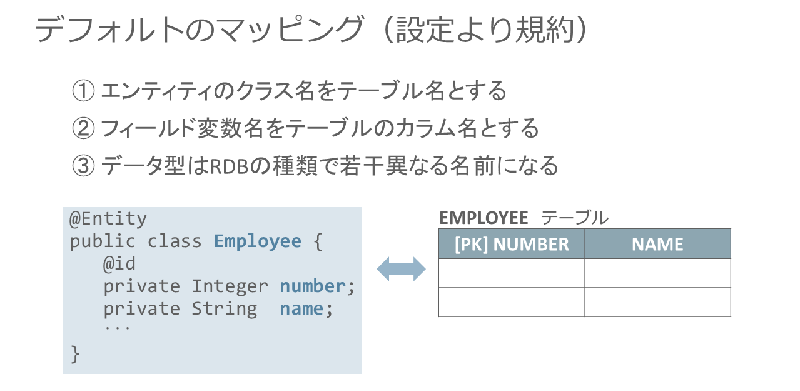
※クリックすると拡大画像が見られます
マッピングをもう少しきめ細かく指定したい場合に備え、デフォルト設定を変更するためのアノテーションも用意されています。ここでは、それらについての説明は割愛しますが、どのようなアノテーションがあるのかを下表にまとめましたので参考にしてください。
【表2:デフォルトのマッピングを変更するためのアノテーション】
| アノテーション名 | 説明 |
|---|---|
| テーブルの構成を指定するアノテーション | |
| @Table | RDBのテーブル名を指定する。カラムに対する制約なども指定できる |
| @Secondarys @Secondary @Column |
エンティティを複数のRDBテーブルに分割する |
| @Embeddable @Embedded |
複数のクラスで1つのエンティティを構成する |
| 主キーを指定するアノテーション | |
| @Id @GeneratedValue |
主キーの自動生成を指定する |
| @Embeddable @EmbeddedId |
@Embeddableを付けたクラスのオブジェクトを主キーにする。次の@IdClass、@Idを使う方法とはエンティティで主キーに指定する方法が異なるだけで実質的には同じもの。こちらの方法のほうが簡単 |
| @IdClass @Id |
@IdClassを付けたクラスのオブジェクトを主キーにする |
| フィールドに個別の属性を指定するアノテーション | |
| @Column | フィールドに対応するテーブル・カラムを指定する |
| @Basic | 遅延フェッチを指定する |
| @Lob | ファイルなど大きいデータであることを示す |
| @Enumerated | 列挙を、名前と序数のどちらで記録するか指定する |
| @TemporalType | Date/Calendar型の値のデータベース型を指定する |
| @ElementCollection | 基本型のList、Set、MapをRDBに割り付ける |
| @CollectionTable | 割り付け先のテーブル名を指定する |
| @MapKeyColumn | 割り付け先テーブルでのキー・カラム名を指定する |
| @Column | 割り付け先テーブルでのカラム名を指定する |
| @Transient | データベースに保存しないフィールドを指定する |
JPA使いこなしの肝「オブジェクト/リレーショナル・マッピング」
続いて、JPAを使いこなすうえでの肝となるオブジェクト/リレーショナル・マッピングについて説明します。JPAのオブジェクト/リレーショナル・マッピングには、次の5つのタイプがあります。
- One-to-One(片方向)
- One-to-Many(片方向)
- One-to-One(双方向)
- One-to-Many/Many-to-One (双方向)
- Many-to-Many(双方向)
以下、それぞれのポイントを簡単に見ていきましょう。
(1)One-to-One(片方向)のマッピング
「One-to-One」とは、例えば「Customer(顧客)」オブジェクトと「Information(顧客情報)」オブジェクトを「1対1」の関係で結ぶことを意味します。
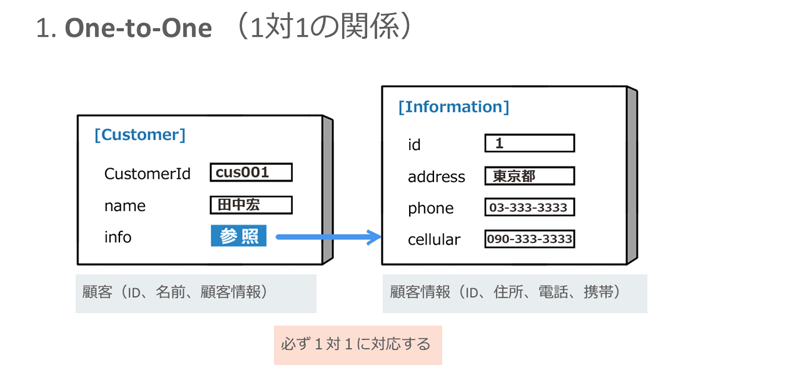
※クリックすると拡大画像が見られます
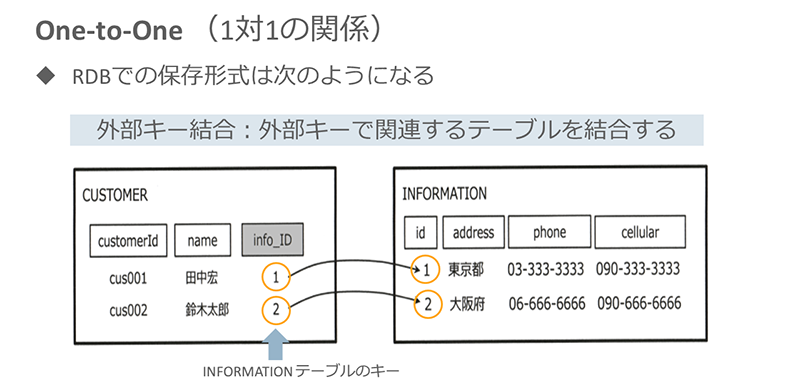
※クリックすると拡大画像が見られます
1対1関係のエンティティの定義は、通常のJavaクラスを定義するのと同じです。上図のクラスCustomerとInformationなら、それぞれ下図のように定義します。

※クリックすると拡大画像が見られます
また、これらのエンティティを使ったプログラム側の永続化処理は、次のように定義します。
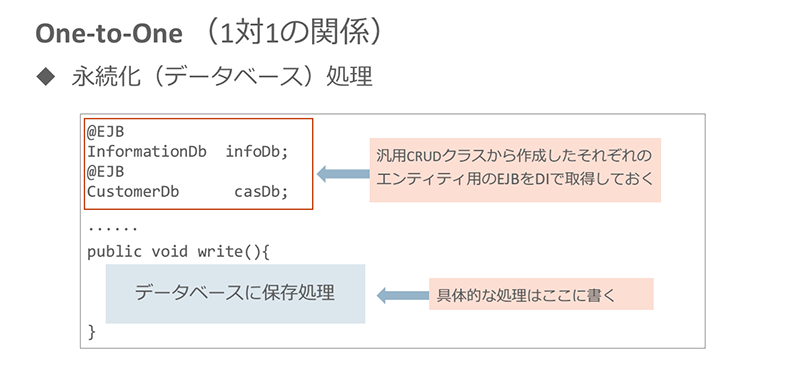
※クリックすると拡大画像が見られます
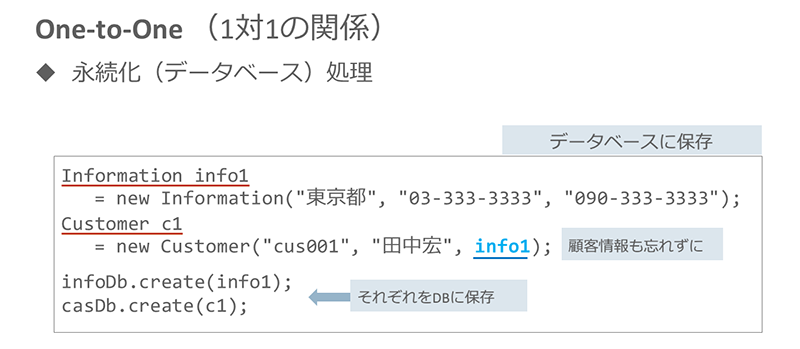
※クリックすると拡大画像が見られます
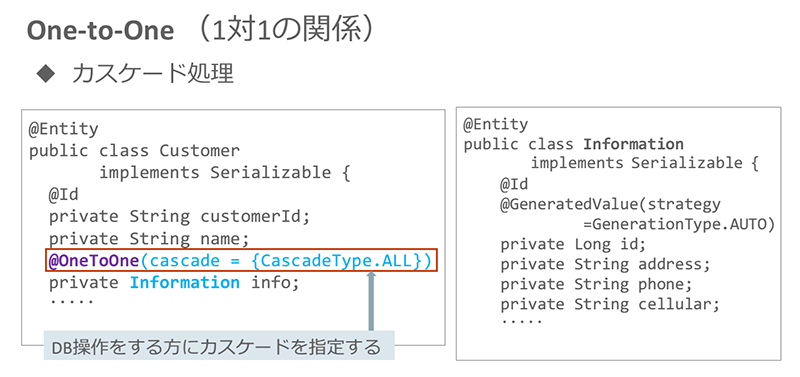
ここでポイントとなるのは、データベース操作を実行するクラス(この例では、クラスCustomer)にカスケード処理を指定することです。カスケードの指定は次のように行います。
【リスト2:カスケードの指定】
@OneToOne(cascade = {…略…})
例えば、カスケード指定を「cascadeType.ALL」と書けば、Customerオブジェクトに対するデータ操作(登録、更新、削除など)が、すべてInformationオブジェクトに連動するようになります。
※クリックすると拡大画像が見られます
なお、カスケード処理には、下表に示すようにさまざまなタイプがあります。
【表3:カスケード指定のタイプ】
| カスケード指定 | カスケードするイベント | 対応するメソッド |
|---|---|---|
| CascadeType.PERSIST | 新規保存 | persist |
| CascadeType.MERGE | 更新 | merge |
| CascadeType.REMOVE | 削除 | remove |
| CascadeType.REFRESH | 永続性コンテキストのエンティティをデータベースから再取得した値で更新する | refresh |
| CascadeType.DETACH | 永続性コンテキストからエンティティを分離する | detach |
| CascadeType.ALL | 上記のすべての操作を指定する |
これらをさまざまに組み合わせて、独自のカスケード指定を作ることもできます。
(2)One-to-Many(片方向)のマッピング
「One-to-Many(1対多)」のマッピングは、例えば1つの「注文(Cart)」に複数の「注文明細(Orderline)」をひも付けるといった場合に使用します。
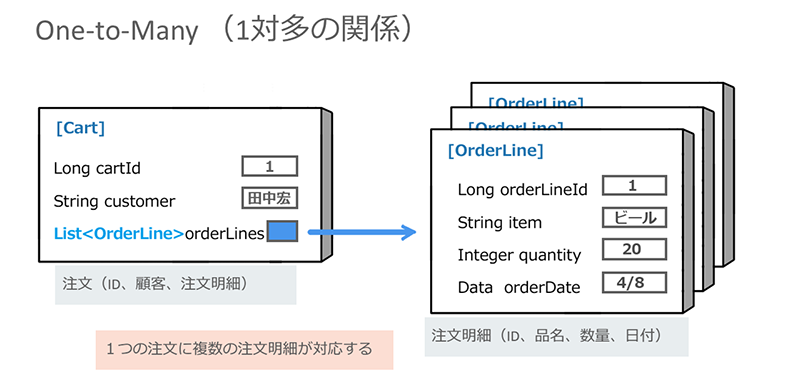
※クリックすると拡大画像が見られます
このタイプのエンティティを定義する際のポイントも、One-to-Oneの場合と同様、データベース操作を実行するクラス(Cart)にカスケードを指定する点です。指定の方法は、「@OneToMany(cascade = {…略…})」と「@ManyToOne(cascade = {…略…})」のどちらでもかまいません。
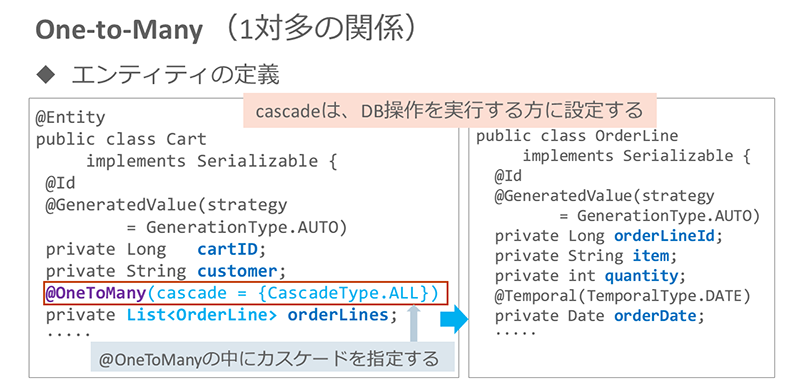
※クリックすると拡大画像が見られます
(3) One-to-One(双方向)のマッピング
One-to-Oneのマッピングは、2つのオブジェクトが互いに参照し合う双方向型にすることもできます。
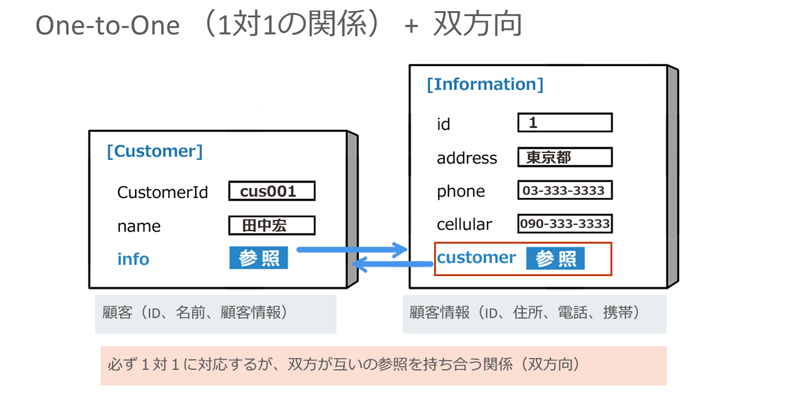
※クリックすると拡大画像が見られます
このタイプのエンティティを定義する際のポイントとしては、次の2つが挙げられます。
- データベース操作を実行するクラスに「@OneToOne(cascade = {…略…})」を付ける
- いずれかのクラスに「@OneToOne(mappedBy = …略…)」を付ける
このうち、なぜmappedByの指定が必要なのかというと、双方向の参照関係にあるオブジェクトは互いに相手のオブジェクトを保持しているため、mappedByの指定がないと片方向の参照(外部キー結合の構造)が2つできてしまうからです。その無駄を避けるために、mappedByをどちらか一方のクラスに指定して、そのクラスを"関係の被所有者"とし、もう一方を"関係の所有者"とする必要があるのです。

※クリックすると拡大画像が見られます
(4)One-to-Many/Many-to-One(双方向)
「One-to-Many/Many-to-One(双方向)」の関係を、先ほどの「Cart(注文)」と「Orderline(注文明細)」の関係を例にとって表すと、「1つ1つのOrderlineにCartの情報を持たせ、明細を見れば、どの注文かがわかるようにする」といった具合になります。
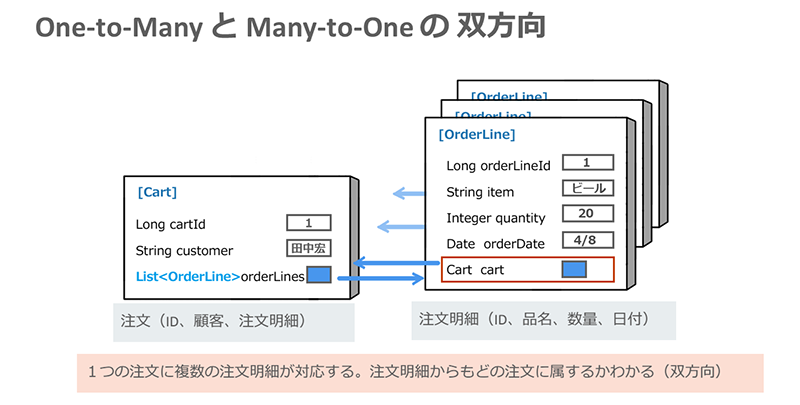
※クリックすると拡大画像が見られます
このタイプのエンティティを定義する際のポイントもmappedByの定義をクラスに付与することとなります。ただし、「One-to-One(双方向)」の場合とは異なり、mappedByの指定は必ず「One-to-ManyのMany側」に記述します。指定形式はOne-to-One(双方向)と同じく「OneToOne(mappedBy = …略…)」となります。

※クリックすると拡大画像が見られます
(5)Many-to-Many(双方向)
最後の「Many-to-Many(双方向)」とは、エンティティが「多対多」の関係で相互に結ばれるというものです。この関係を使うケースは少ないでしょうが、例えば「俳優(Actor)」と「映画(Movie)」を関連付ける場合などが考えられます。
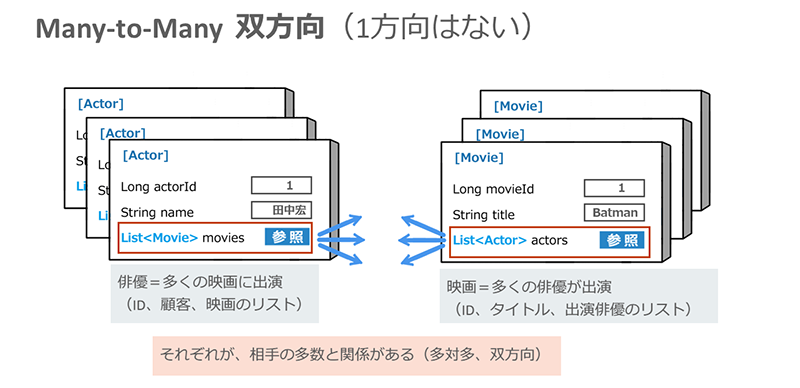
※クリックすると拡大画像が見られます
このタイプのエンティティ定義は次のように行います。

※クリックすると拡大画像が見られます
ここでも、mappedbyを指定することがポイントとなりますが、記述するクラスは「One-to-One(双方向)」の場合と同様、どちらのクラスでもかまいません。
JPAのクエリ言語「JPQL」の基本
JPAで使用するクエリ言語JPQLについても説明しておきましょう。JPQLは、"SQLのオブジェクト版"とも呼ぶべきもので、SQLを使える人ならば簡単に理解できます。
例えば、先の「One-to-Many(双方向)」で示した「Cart(注文)」と「Orderline(注文明細)」のケースでJPQLを使うことを考えてみます。このケースにおいて、例えば「田中さんの明細書を引き出す」というSELECT文を書くと、次のようになります。
【リスト3:「田中さんの明細書を引き出す」ためのSELECT文】
select c from Cart c where c.name = ‘田中’
ご覧のとおり、「c」というオブジェクトを使っている以外は、通常のSQL文とほとんど変わりません。以下に、このクエリ文のポイントを挙げます。
- cはエンティティ(この例では、Cart)の別名(エイリアス)である
- SELECT句にエイリアスを指定すると、全件を取得する(この例の場合、Cartのオブジェクト全件を取得する)という意味になる
- WHERE句などでは、エイリアスのプロパティ(フィールド名)を使って記述する
また、WHERE句では、下表に示すようなSQLでもおなじみの演算子を利用できます。
【表4:JPQLで使用可能な演算子の例】
| 演算子 | 備考 |
|---|---|
| = | c.name='山田' |
| > >= |
c.price>1000 |
| < <= |
c.price<=500 |
| <> | c.price <> 1000 |
| BETWEEN | c.price BETWEEN 100 and 1000 |
| LIKE | 文字列の一致を検査する |
| IN | 括弧内のリストに該当するものがあるかどうか |
| IS NULL | |
| IS EMPTY | |
| AND OR NOT() |
JPQLは、オブジェクト指向言語ならではの優れた特徴も備えています。その1つが、「関係のあるエンティティでは、自動的にJOIN機能が働く」というものです。例えば、次のJPQL文をご覧ください。
【リスト4:JPQLで書いたクエリの例(JOINを省略)】
select o from OrderLine o where o.cart.customer = '田中宏'
このシンプルさは、JOIN機能が自動的に働くことで実現されています。もしJOINを明示的に使うとしたら、次のような文を書かなくてはなりません。
【リスト5:リスト4と同じ内容を、JOINを明示的に使って書いた例】
select o from OrderLine o join Cart c on o.cart.cartID = c.cartID where o.cart.customer = '田中宏'
さらに、JPQLではCOUNT、MAXといった集計関数も使うことができます。ただし、エンティティ以外に対して使った場合、取得する値は配列型のObject[]型となり、キャストが必要なため記述が面倒になります。
【リスト6:集計関数を使ったJPQL文の例】
Object[] array = select c.customer, count(c) from OrderLine o join Cart c on o.cart = c group by c
コーディングを簡単にするには、結果のマッピングを行うための次のようなクラスを作っておくとよいでしょう。
【リスト7:集計関数で取得したオブジェクトのキャストを行うためのユーティリティ・クラス】
package bean; public class Sum{ private String name; private long count; public Sum(String name, long count){ this.name = name; this.count = count; } // setter/getterメソッドなど }
そのうえで、このクラス(Sum)のコンストラクタで処理結果を受け、List<Sum>に渡すようにすると便利です。

※クリックすると拡大画像が見られます
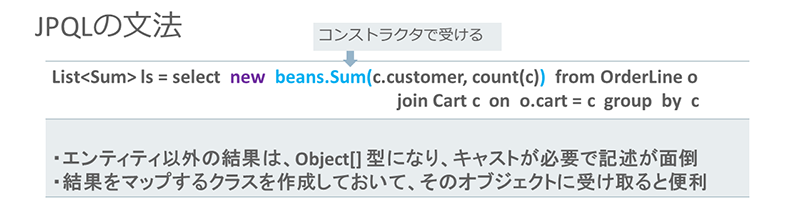
※クリックすると拡大画像が見られます
加えて、「SELECT DISTINCT」と「JOIN FETCH」の組み合わせと使うと、例えば「Cartオブジェクトと、それにひも付くOrderLine(複数)を一度に取得する」といったクエリを生成することができます。
【リスト8:Cartオブジェクトと、それにひも付くOrderLine(複数)を一度に取得するためのJPQL文】
select distinct c from Cart c join fetch c.orderLines
これは、「One-to-Many」の関係における「N+1問題」、つまり「Cartエンティティからすべてのデータを取得しようとすると、CartエンティティごとにOrderlineエンティティを取得するためのSQL文が生成されてしまう」という問題を回避するための書き方です。
1つ注意点も挙げておきます。JPQLを使う際には、必ずSQLのログを確認することを忘れないでください。その理由は、JPQLからSQLへの変換により、無駄なSQL文が生成される場合があるためです。SQLのログを取るには、JPAの設定ファイルであるpersistence.xmlに次のような設定を記述しておきます。
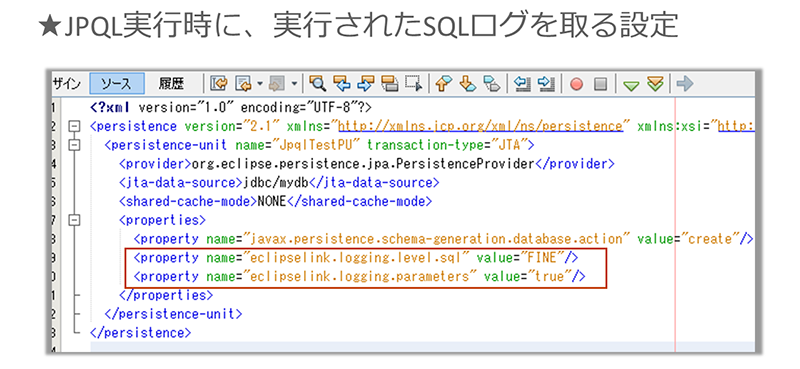
※クリックすると拡大画像が見られます
JPQLの使い方
JPQLを使うには、まずエンティティ・クラスにJPQL文を記述します。このとき、プログラム実行時にパラメータの値をセットできるように指定することも可能です。

※クリックすると拡大画像が見られます
そして、JPQLを実行するメソッドを定義したEJBクラスを作ります。

※クリックすると拡大画像が見られます
このEJBクラスでエンティティのJPQL文を呼び出してクエリを生成し、パラメータの値をセットするわけです。クエリの実行結果は、getResultListなどのメソッドで受け取ります。
以上、駆け足となりましたが、JPAの基本的な事項について説明しました。ご覧いただいたように、JPAはとても使いやすく、シンプルなAPIです。これからJava EE開発に取り組む皆さんは、ぜひJPAをご活用ください。