今回もサンプルはFlowableを使って実装していますが、Observableの場合もバックプレッシャーを扱わない限り、基本的にはほぼ同じ使い方になります。また、データを受け取るSubscriberとして、特別なことをしない限り、第5回で作成したDebugSubscriberを使用しています。
対象読者
- Java経験者(初心者可)
- RxJava未経験者
- リアクティブプログラミング未経験者
※ ただし、前回までの連載を読んでいる前提です。
RxJavaの非同期処理
RxJavaでは開発者が非同期処理の設定やオペレータ内で時間を扱う処理を行わない限り、基本的には生産者(Flowable/Observable)の処理が実行されるスレッド上で、各オペレータの処理や消費者(Subscriber/Observer)の処理が行われます。つまり、生産者がデータを生成してそのデータを通知するまで後続の処理は処理を行えず待機することになり、そのデータを受け取ったオペレータや消費者が処理をしている間、元の生産者やその他のオペレータはデータを受け取った側の処理が終わるまで待っていることになります。それに対し、開発者が非同期処理の設定をすることで、生産者、オペレータ、消費者のそれぞれがお互いの処理を待つことなく自分自身のペースで処理を行えるようになります。
また、RxJavaのオペレータの中にはflatMapメソッドのように内部でFlowable/Observableを生成するものもあります。その際に内部で生成するFlowable/Observableが異なるスレッド上で処理を行うものの場合、通知データの生成処理はそれぞれの処理が一つずつ順番に行われるわけではなく、あるデータの生成処理中に別のデータの生成処理も実行されるようになります。そして、結果となるデータは処理が終わった順に通知されていきます。そのため、このことを意識していないと結果のデータが元の通知順と同じように通知されなくなる可能性があるため、注意が必要です。
加えて、バージョン2.0.5より並列処理を行うための新しいParallelFlowableが追加されました。今回はこの新しいParallelFlowableについても簡単に紹介します。ただし、この機能はまだベータ(BETA)版であるため、後のバージョンアップで変わる可能性は高いです(今回は2.1.2で検証しています)。
RxJavaの非同期処理について主に以下を見ていきます。
- 開発者による非同期処理の設定方法
- オペレータ内で生成される非同期のFlowable/Observable
- 2.0.5より追加されたparallelモード(並列モード)
開発者による非同期処理の設定方法
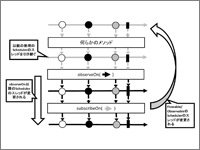
RxJavaで非同期処理を行う場合は、生産者が処理を行うスレッドとデータを受け取る側のスレッドの、2つのポイントについて管理する必要があります。RxJavaでは生産者が処理を実行するスレッドの種類を設定できるsubscribeOnメソッドと、データを受け取る側のスレッドの種類を設定できるobserveOnメソッドを提供しています。これらのスレッドの種類を設定するには、用途に応じたスレッドの管理を行うSchedulerを指定します。
subscribeOnメソッドおよびobserveOnメソッドと比べると使用頻度は低くなると思いますが、cancelメソッドやdisposeメソッドを呼んだ後に実行される、購読解除の処理を行う時(doOnCancel)のSchedulerを設定するunsubscribeOnメソッドもあります。unsubscribeOnメソッドは、このメソッドの後に設定されているdoOnCancelメソッドには適用されないので注意してください。
Scheduler
SchedulerはRxJavaで用意されているスレッドを管理するクラスです。RxJavaでは基本的に直接Java標準のAPIを触らず、Schedulerを使って非同期処理を行うことができるようになっています。このSchedulerは用途によっていくつかの種類が用意されており、目的のSchedulerを取得するためのメソッドを持つSchedulersによって必要なSchedulerを取得します。また、Java標準のAPIにあるjava.util.concurrent.Executorを使ってそのExecutorを使ったSchedulerを作成することも可能です。
| Schedulersが持つ取得メソッド | 概要 |
|---|---|
| computation() | コンピューティング処理を行う際に使うScheduler。デフォルトではスレッドプールに論理プロセッサ数と同じ数のスレッドを用意し、それらのスレッドを使いまわす。 ※I/O用の処理では使わない。 |
| io() | I/Oの処理を行う際に使うScheduler。基本的にスレッドプールからスレッドを取得し、スレッドプールになければ新規のスレッドを生成する。 |
| single() | 単一のスレッドのみ用意し、そのスレッドしか使わないScheduler。 |
| newThread() | 毎回新しいスレッドを生成するScheduler。 |
| from(Executor executor) | 指定したExecutorから生成されるスレッド上で処理をするScheduler。 |
| trampoline() | 呼び出し元のスレッドに新たな処理をキューとして入れるScheduler。既に他の処理がキューに入っていれば、その処理が終わってから実行される。 |
subscribeOnメソッド
subscribeOnメソッドは最初にデータを生成し通知する元となる生産者(Flowable/Observable)の処理を、どのようなScheduler上で行うのかを設定するオペレータです。

現在、安定版として公開されているsubscribeOnメソッドは以下になります。
- subscribeOn(Scheduler scheduler)
subscribeOnメソッドは生産者が行う処理のSchedulerを設定する性質上、1回しか設定できません。一度、subscribeOnメソッドを使ってSchedulerを設定すると、それより後に指定したsubscribeOnメソッドのSchedulerは無視されます。
public static void main(String[] args) throws Exception { Flowable.just(1, 2, 3, 4, 5) // Flowableの設定 .subscribeOn(Schedulers.computation()) // RxComputationThreadPool .subscribeOn(Schedulers.io()) // RxCachedThreadScheduler .subscribeOn(Schedulers.single()) // RxSingleScheduler .subscribe(data -> { String threadName = Thread.currentThread().getName(); System.out.println(threadName + ": " + data); }); // しばらく待つ Thread.sleep(500); }
RxComputationThreadPool-1: 1 RxComputationThreadPool-1: 2 RxComputationThreadPool-1: 3 RxComputationThreadPool-1: 4 RxComputationThreadPool-1: 5
この結果より、先の例ではSchedulers.computation()のSchedulerが設定されていることがわかります。ただしこのサンプルのように、subscribeOnメソッドで何度もSchedulerを設定することは混乱の原因になるので避けるべきです。また、一度しか設定できない性質により、intervalメソッドで生成された生産者のようにデフォルトで生産者のSchedulerが指定してある場合は、開発者がsubscribeOnメソッドで異なるSchedulerを設定しても、そのSchedulerの設定は反映されないことを注意しないといけません。元からデフォルトのSchedulerが設定される生産者の場合、その生成メソッドの引数にSchedulerを受け取るものが用意されており、そこに指定したSchedulerを設定することで意図したScheduler上で処理を行う生産者が生成できます。
observeOnメソッド
observeOnメソッドはデータを受け取った側の処理をどのようなScheduler上で行うのかを設定するメソッドです。observeOnメソッドで指定したSchedulerが設定したスレッド上で、それ以降の処理を行うようになります。また、observeOnメソッドがデータを受け取る側のSchedulerを指定するため、オペレータごとに異なるSchedulerを指定することが可能です。

observeOnメソッドにはSchedulerのみを引数に取るものを含め、以下のメソッドが用意してあります。引数が省略してあるメソッドは、デフォルト値の設定になります。
- observeOn(Scheduler scheduler)
- observeOn(Scheduler scheduler, boolean delayError)
- observeOn(Scheduler scheduler, boolean delayError, int bufferSize)
| 引数No | 引数の型 | 説明 |
|---|---|---|
| 第1引数 | Scheduler | スレッド管理を行うクラス。 |
| 第2引数 | boolean | trueの場合はエラーが発生しても、そのことをすぐには通知せず、バッファしているデータを通知し終えてからエラーを通知する。falseの場合は発生したらすぐにエラーを通知する。デフォルトはfalse。 |
| 第3引数 | int | 通知待ちのデータをバッファするサイズ。デフォルトでは128。 |
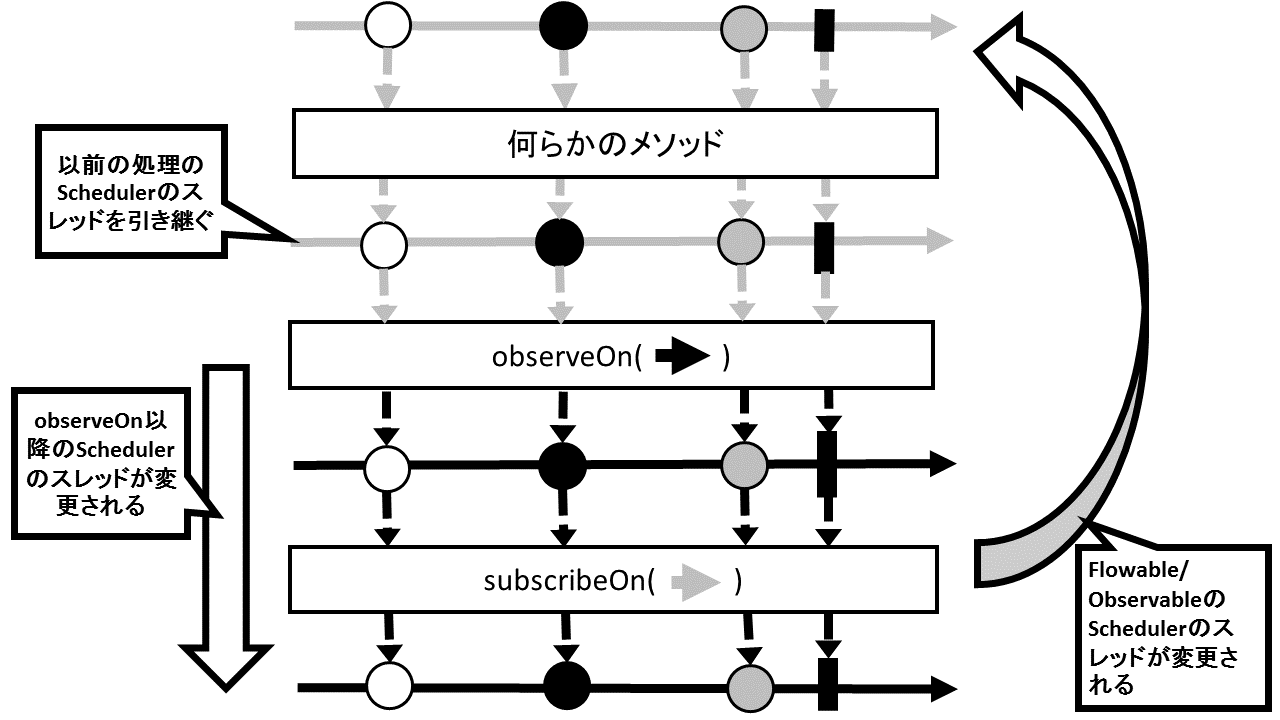
RxJavaでバックプレッシャーを扱う際に特に重要になるのが第3引数で、消費者に通知されるデータは、このバッファされた通知待ちのデータから取得されることになります。ここで指定した数値が、通知側に対してデータ数のリクエストを自動で行うようになっており、そのリクエストを受けて送られたデータがバッファされることになります。つまり「2」を指定すると、内部でrequest(2)が実行されていることになります。以下の図ではBackpressureStrategy.DROPが設定してある生産者に対して、observeOnメソッドのbufferSizeに「2」が指定されています。これは、observeOnメソッドの下流にある消費者がデータ数のリクエストをLong.MAX_VALUEにしても、observeOnメソッド側でリクエストして受け取ったデータしか消費者に通知されないことを表しています。消費者はobserveOnメソッドが持つ全てのデータを受け取ることになりますが、生産者側のデータに関しては全て受け取れるわけではないことを表しています。
第3引数を設定しない場合は最初にデフォルトの128件のデータ数についてリクエストを行い、データの通知が75%(デフォルトだと96件)に達したタイミングで元のデータ数の75%分についてリクエストをすることを繰り返し行います。
unsubscribeOnメソッド
unsubscribeOnメソッドは、Flowable/Observableがcancelメソッドやdisposeメソッドが呼ばれて購読を解除された際の処理を、引数に指定したSchedulerのスレッド上で実行するオペレータです。これは、doOnCancel/doOnDisposeメソッドで定義した処理やcreateメソッドで通知処理を行うEmitterで設定したCancellableやDisposableの処理が購読解除した際に、unsubscribeOnメソッドの引数におけるSchedulerのスレッド上で実行されるようになります。ただし、完了やエラーで処理を終了した場合にはこのSchedulerは使われません。

オペレータ内で生成される非同期のFlowable/Observable
RxJavaのメソッドの中には、flatMapメソッドのようにオペレータの中でFlowable/Observableを生成し、それを起動してデータを通知するメソッドがあります。その際、そこで生成しているFlowable/Observableが別スレッド上で実行される場合、データを受け取りそこで生成したFlowable/Observableを起動するところまでは順番に実行されますが、起動されたFlowable/Observableはそれぞれ異なるスレッド上で処理を行います。つまり、使っているメソッドによっては複数のFlowable/Observableが異なるスレッド上で同時に実行されることを意味します。そのため、メソッドによってはデータを受け取った順にFlowable/Observableが生成されたとしても、その結果、データが受け取った順に通知されることが保証されません。ここでは、内部でFlowable/Observableを生成するオペレータの中で、flatMapメソッド、concatMapメソッド、concatMapEagerメソッドを見ていき、異なるスレッド上で処理を行うFlowable/Observableを生成した場合に、どのような通知処理の違いがあるかを見ていきます。
flatMapメソッド
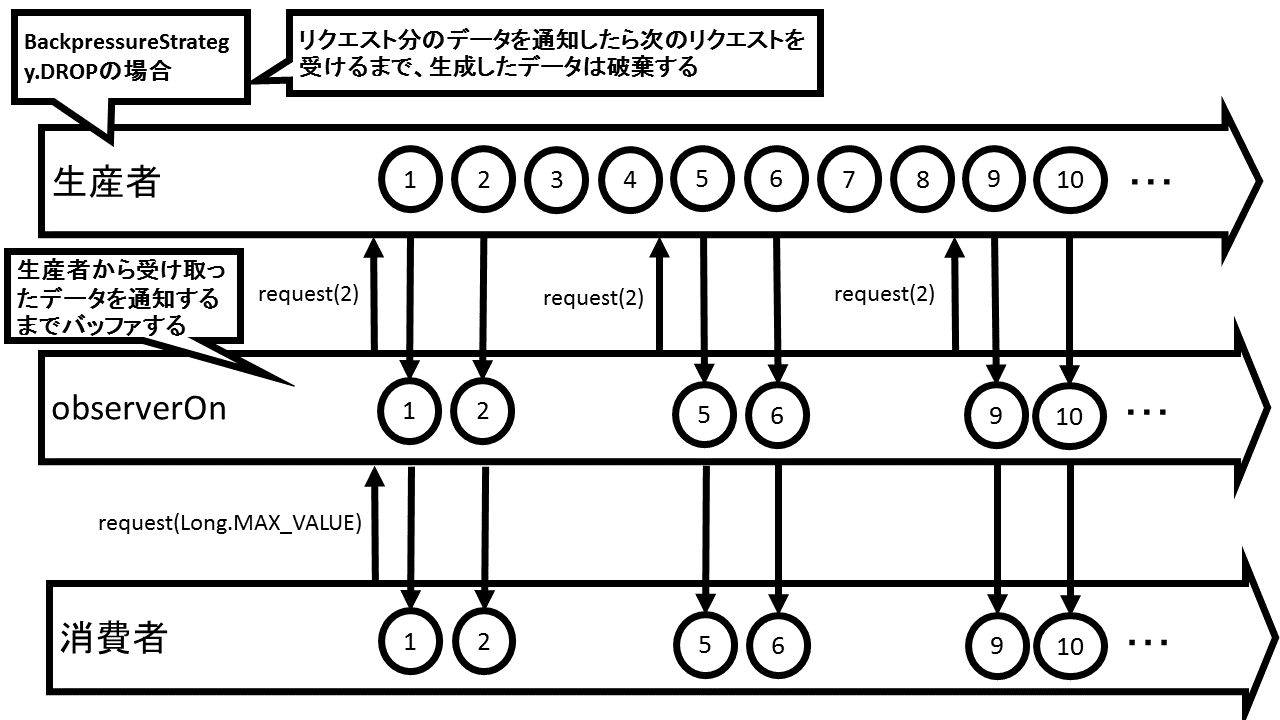
flatMapメソッドはデータを受け取った際、新たにFlowable/Observableを生成して実行し、通知されたデータを結果として通知するオペレータです。そこで生成されるFlowable/Observableが異なるスレッド上で処理を行い、受け取るデータが連続してくる場合、生成したFlowable/Observableが他のFlowable/Observableの処理が終わっているのかどうか関係なく実行され、それぞれの処理が終わったタイミングで、結果としてのデータが通知されます。そのため、最終的に通知するデータはデータを受け取った順に実行されるとは限りません。
例えば、justメソッドから生成した「A」「B」「C」と通知するFlowableがあり、flatMapメソッド内で受け取ったデータからdelayメソッドを使ったFlowableを生成し、各データを1000ミリ秒遅らせて通知しようとしているとします。その場合、順番にデータを受け取り、そのデータからFlowableを生成して起動するまで、ほぼ時間をかけずに実行できます。つまり、ほぼ同時に異なるスレッド上で処理を行う複数のFlowableを実行することになります。しかし、JavaではCPUの負荷などの影響もあり正確な時間で処理を行うことはできません。スレッドによっては処理のスピードが遅くなることもあります。それにより、遅れたスレッド上のデータより別のスレッド上のデータが先に通知され、通知される順がデータを受け取った順と同じになるとは限らなくなります。
public static void main(String[] args) throws Exception { Flowable<String> flowable = // Flowableの生成 Flowable.just("A", "B", "C") // 受け取ったデータからFlowableを生成し、それが持つデータを通知する .flatMap(data -> { // 1000ミリ秒遅れてデータを通知するFlowableを生成 return Flowable.just(data).delay(1000L, TimeUnit.MILLISECONDS); }); // 購読する flowable.subscribe(data -> { String threadName = Thread.currentThread().getName(); System.out.println(threadName + ": " + data); }); // しばらく待つ Thread.sleep(2000L); }
RxComputationThreadPool-1: A RxComputationThreadPool-3: C RxComputationThreadPool-2: B
実行結果より、通知されているデータは元のデータを受け取った順になっていないことがわかります。データの順番は関係なく、パフォーマンスを重視する場合はflatMapメソッドが使えますが、データの順番が重要である場合はflatMapメソッドは使わない方がよいでしょう。
concatMapメソッド
concatMapメソッドは受け取ったデータから内部でFlowable/Observableを生成し、それを一つずつ順番に実行し、通知されたデータを結果として通知するオペレータです。そのため、そこで生成されるFlowable/Observableがそれぞれ異なるスレッド上で処理を行っても影響を受けず、データを受け取った順に新たなFlowable/Observableのデータを通知するようになります。
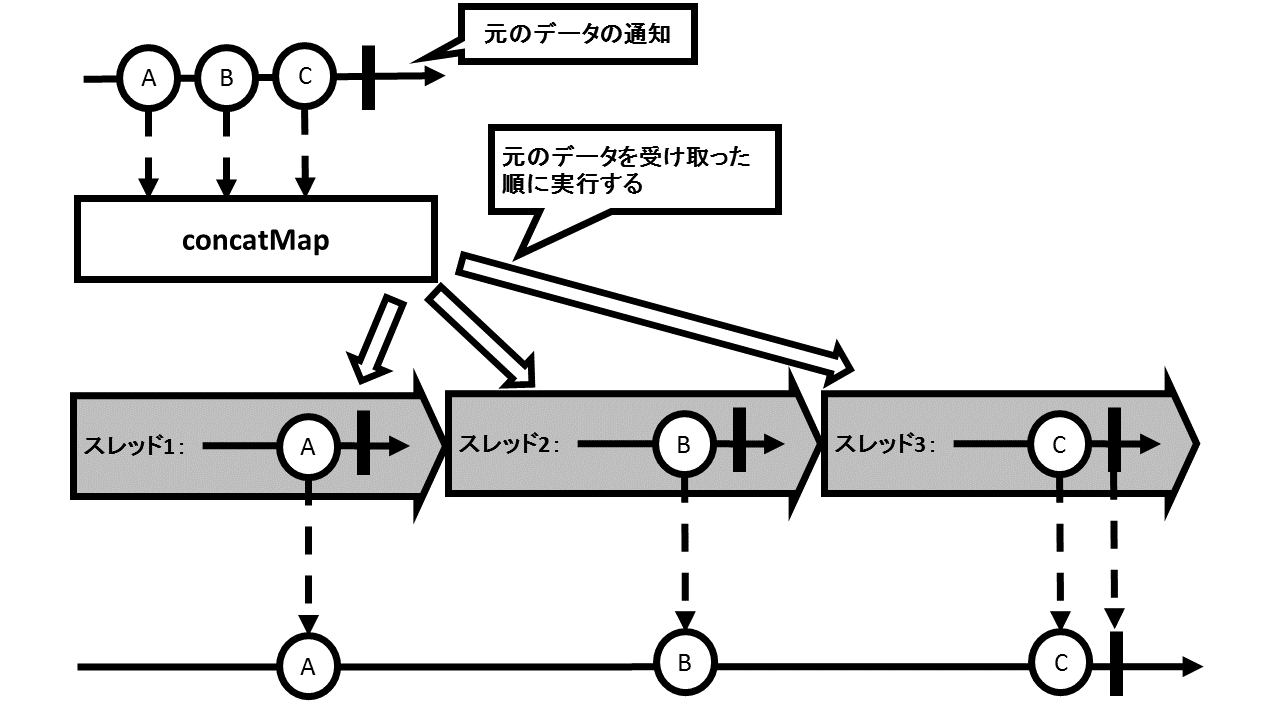
例えば「A」「B」「C」と通知するFlowableがあり、concatMapメソッド内で受け取ったデータからdelayメソッドを使ったFlowableを生成し、そのFlowableが1000ミリ秒遅らせてデータを通知しようとしているとします。その場合、データを受け取ってからFlowableを生成して起動し、そのFlowableの処理が終わるまで次のデータのFlowableを生成しません。Flowableが異なるスレッド上で処理を行っても、そのことに関係なく、受け取ったデータの順番で新しいデータを通知することになります。
public static void main(String[] args) throws Exception { Flowable<String> flowable = // Flowableの生成 Flowable.just("A", "B", "C") // 受け取ったデータからFlowableを生成し、それが持つデータを通知する .concatMap(data -> { // 1000ミリ秒遅れてデータを通知するFlowableを生成 return Flowable.just(data).delay(1000L, TimeUnit.MILLISECONDS); }); // 購読する flowable.subscribe(data -> { String threadName = Thread.currentThread().getName(); String time = LocalTime.now().format(DateTimeFormatter.ofPattern("ss.SSS")); System.out.println(threadName + ": data=" + data + ", time=" + time); }); // しばらく待つ Thread.sleep(4000L); }
RxComputationThreadPool-1: data=A, time=18.152 RxComputationThreadPool-2: data=B, time=19.228 RxComputationThreadPool-3: data=C, time=20.230
実行結果より、元のデータが通知された順に新しいデータを通知することがわかります。そして、データを受け取った間隔がほぼ1秒(1000ミリ秒)ごとになっているのがわかります。このため、パフォーマンスに関係なくデータの順番を重視する場合はconcatMapメソッドが使えます。しかし、パフォーマンスが重要な場合はconcatMapメソッドは使わない方がよいことになります。
concatMapEagerメソッド
concatMapEagerメソッドはデータを受け取ったら、新たにFlowable/Observableを生成してすぐに実行し、そのFlowable/Observableが通知するデータを元のデータを受け取った順に通知するオペレータです。そこで生成されるFlowable/Observableが異なるスレッド上で処理を行う場合、生成したFlowable/ObservableはflatMapメソッドのように同時に実行されることがあります。しかし、結果として通知するデータはconcatMapメソッドのように元のデータを受け取った順になります。

例えば「A」「B」「C」と通知するFlowableがあり、concatMapEagerメソッド内で受け取ったデータからdelayメソッドを使ったFlowableを生成し、そのFlowableが1000ミリ秒遅らせてデータを通知しようとしているとします。その場合、順番にデータを受け取り、そのデータからFlowableを生成して起動するまで、ほぼ時間をかけずに実行できます。しかし、結果として通知するデータは内部でFlowableが生成された順のため、通知されるまで生成されたデータがバッファされることになります。
public static void main(String[] args) throws Exception { Flowable<String> flowable = // Flowableの生成 Flowable.just("A", "B", "C") // 受け取ったデータからFlowableを生成し、それが持つデータを通知する .concatMapEager(data -> { // 1000ミリ秒遅れてデータを通知するFlowableを生成 return Flowable.just(data).delay(1000L, TimeUnit.MILLISECONDS); }); // 購読する flowable.subscribe(data -> { String threadName = Thread.currentThread().getName(); String time = LocalTime.now().format(DateTimeFormatter.ofPattern("ss.SSS")); System.out.println(threadName + ": data=" + data + ", time=" + time); }); // しばらく待つ Thread.sleep(2000L); }
RxComputationThreadPool-1: data=A, time=20.340 RxComputationThreadPool-1: data=B, time=20.353 RxComputationThreadPool-1: data=C, time=20.354
実行結果より、元のデータが通知された順に新しいデータを通知することがわかります。そして、データがほぼ同時に通知されていることもわかります。このため、データの順番とパフォーマンスの両方を重視する場合に、concatMapEagerメソッドは適しているといえます。しかし、内部で生成されたFlowable/Observableが完了を通知までに、次以降のFlowable/Observableが生成したデータをバッファすることになるので、大量のデータがバッファされるとMissingBackpressureExceptionが発生するリスクや、メモリが足りなくなるリスクがあります。
2.0.5より追加されたParallelFlowable
RxJavaではバージョン2.0.5より新しい機能としてParallelFlowableが追加されました。この機能はFlowableにしかなく、mapオペレータやfilterオペレータなどのいくつかの機能を並列して実行できるようにする機能です。この並列して実行する機能(並列モード)とは、受け取ったデータを一つずつ順に実行するのではなく、受け取ったデータをそれぞれ異なるタイムライン(公式のサイトでは「rail(レール)」と呼ばれている)に分配して、複数のレール上で分配したデータを処理するようにすることです。ここでは、このParallelFlowableについて見ていきましょう。
※今回はRxJava 2.1.2で検証しています。
ParallelFlowableの概要
並列モードで処理を行えるようにするには、まず元となるFlowableからParallelFlowableを生成しなければなりません。このParallelFlowableは、通常のFlowableと異なり、各データを異なるレールに分配して処理を行うようにするものです。つまり、ParallelFlowableは複数のSubscriberを持つことになります。
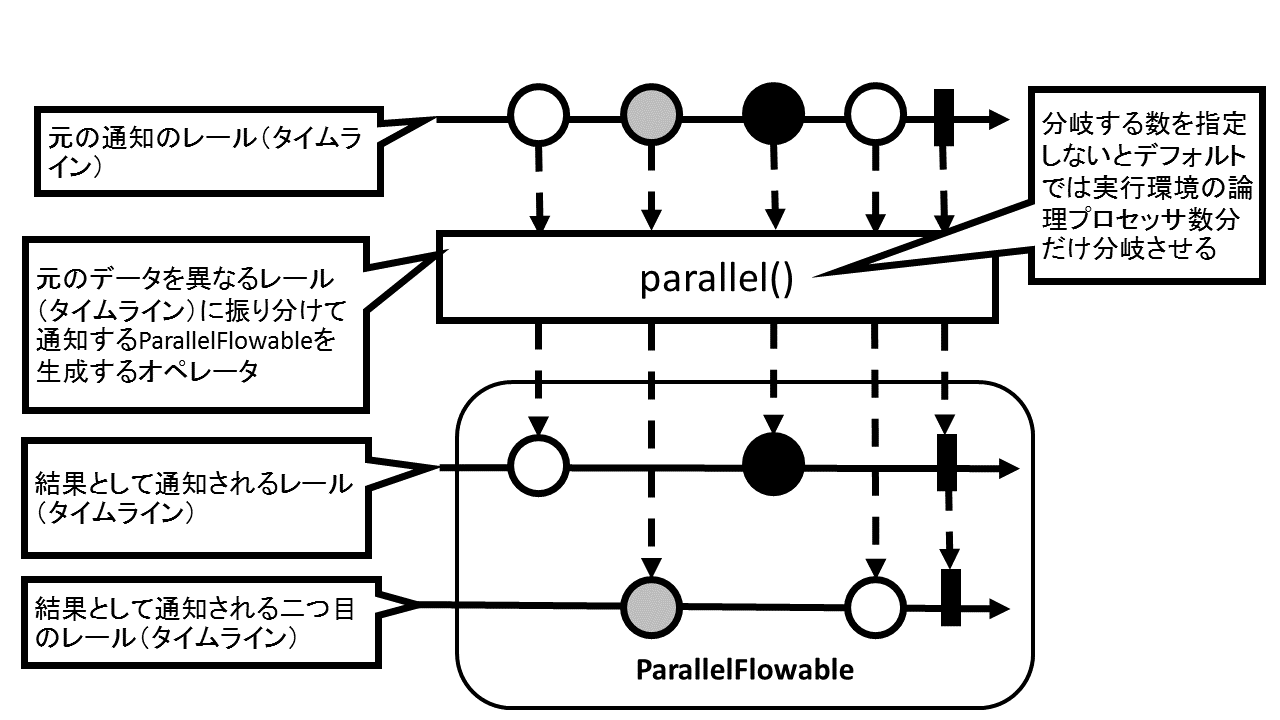
これは複数のSubscriberに同じデータを通知する「Hot」なFlowableと異なり、1つのデータは1つのSubscriberのみに通知され、別のデータは別のSubscriberに通知されるように、各Subscriberは異なるデータを受け取ることになります。
このParallelFlowableを生成するにはFlowableに追加されたメソッドであるparallel()を呼び出すか、ParallelFlowableのstaticな生成メソッドであるfrom(Publisher<T> flowable)を呼び出すことで、元のFlowableをParallelFlowableに変換することができます。また、引数に分岐するレールの個数(parallelism)も指定でき、指定をしない場合はその実行環境の論理プロセッサ数が設定されます。
主なParallelFlowableの生成メソッド
-
Flowable#parallel() -
Flowable#parallel(int parallelism) -
ParallelFlowable#from(Publisher<T> flowable) -
ParallelFlowable#from(Publisher<T> flowable, int parallelism)
※PublisherはFlowableが実装しているインターフェース
これらのデータを受け取った際の処理をそれぞれ異なるスレッド上で実行することで、あるデータの処理が終わっていなくても、次のデータの処理を実行することが可能になります。つまり、各レールの処理を異なるスレッド上で行うことで、異なるデータを受け取った複数の処理を並列して実行できるようになります。逆に、生成したParallelFlowableに対してSchedulerを設定せずに処理を行うと、データを通知するスレッドと同じスレッド上で処理を行うことになるため、1つのデータの処理が終わるまで次のデータの処理を始めることができなくなってしまいます。このParallelFlowableが処理を行うSchedulerを設定するにはParallelFlowableのrunOnメソッドを使います。
Scheduler設定メソッド
-
runOn(Scheduler scheduler)
加えて、ParallelFlowableが異なるレール上で生成したデータをマージして、1つのレールに通知する通常のFlowableに変換することも可能です。それにより、オペレータ上での処理は並列で実行し、最終的にSubscriberに通知する際は1つのSubscriberだけに通知することが可能になります。
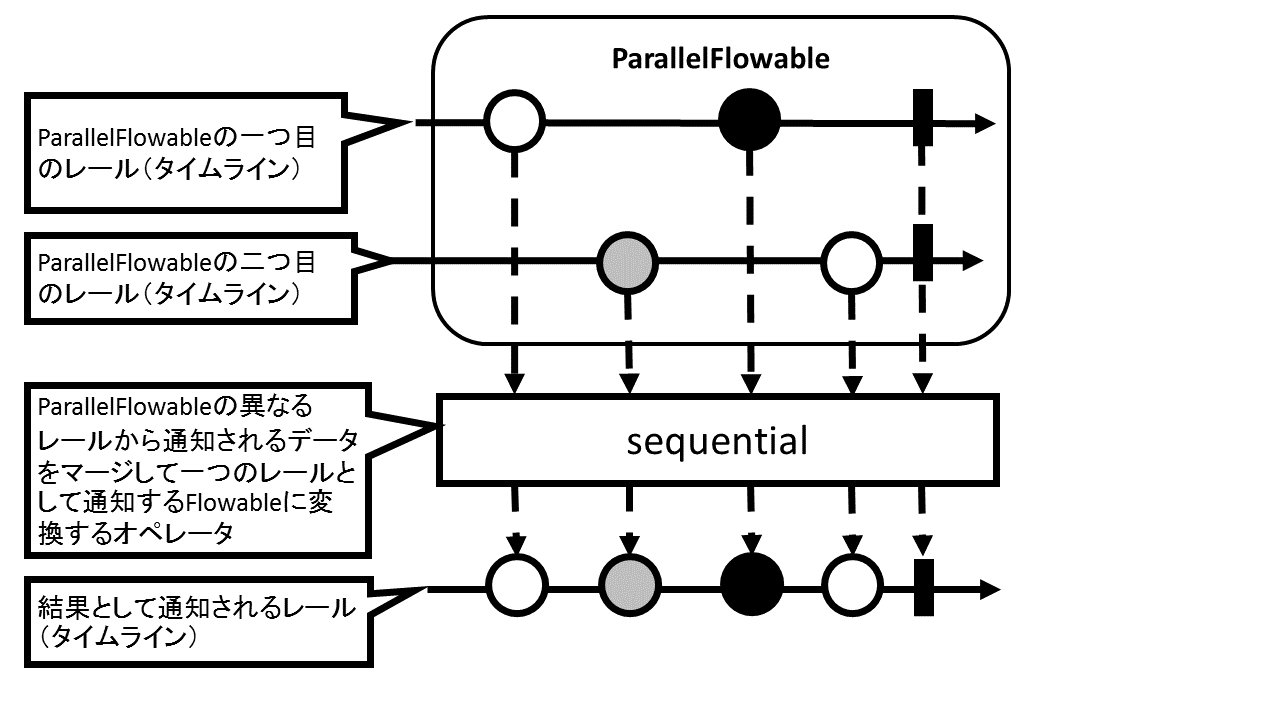
このようにParallelFlowableからFlowableに変換するには、ParallelFlowableのsequential()を呼び出します。
Flowableへの変換メソッド
-
sequential()
注意点として、並列処理を異なるスレッド上で実行する場合、後から通知されたデータの処理が先に終わることがあります。そのため、結果として通知されるデータは元のFlowableが通知したデータ順になっていない可能性があることを認識する必要があります。
ParallelFlowableを使った簡単なサンプル
次のサンプルでは、「1」から「5」までの数値を通知するFlowableからprallelメソッドを使ってParallelFlowableを生成し、受け取ったデータを10倍にするよう異なるスレッド上で処理を行います。最後にそのParallelFlowableが処理を行ったデータをマージし、通知するFlowableに変換してデータを通知するようにしています。また、ParallelFlowableがデータを通知する際にdoOnNextメソッドを通して、どのスレッド上で処理を行っているのかを出力しています。
public static void main(String[] args) throws Exception { // 元となるFlowableからParallelFlowableを生成する ParallelFlowable<Integer> parallelFlowable = // 元となるFlowable Flowable.range(1, 5) // 並列モードにする .parallel() // (1) // 異なるスレッド上で実行するようにする .runOn(Schedulers.computation()) // (2) // 各データを10倍にする .map(data -> data * 10) // 通知処理をしているスレッドを出力 .doOnNext(data -> { String threadName = Thread.currentThread().getName(); System.out.println( "----- 通知: " + threadName + ": " + data); }); // ParallelFlowableをFlowableに変換する Flowable<Integer> flowable = parallelFlowable.sequential(); // (3) // 購読する flowable.subscribe( // データ受取時の処理 data -> { String threadName = Thread.currentThread().getName(); System.out.println(threadName + ": start: " + data); Thread.sleep(10L); System.out.println(threadName + ": end: " + data); }, // エラー時の処理 e -> e.printStackTrace(), // 完了時の処理 () -> System.out .println(Thread.currentThread().getName() + ": 完了")); // しばらく待つ Thread.sleep(1000L); }
- FlowableをParallelFlowableに変換する
-
ParallelFlowableが行う処理を
Schedulers.computation()から取得したSchedulerが管理するスレッド上で処理を行うようにする - ParallelFlowableをFlowableに変換する
----- 通知: RxComputationThreadPool-4: 40 ----- 通知: RxComputationThreadPool-3: 30 RxComputationThreadPool-4: start: 40 ----- 通知: RxComputationThreadPool-1: 10 ----- 通知: RxComputationThreadPool-2: 20 ----- 通知: RxComputationThreadPool-1: 50 RxComputationThreadPool-4: end: 40 RxComputationThreadPool-4: start: 10 RxComputationThreadPool-4: end: 10 RxComputationThreadPool-4: start: 20 RxComputationThreadPool-4: end: 20 RxComputationThreadPool-4: start: 30 RxComputationThreadPool-4: end: 30 RxComputationThreadPool-4: start: 50 RxComputationThreadPool-4: end: 50 RxComputationThreadPool-4: 完了
実行結果より、ParallelFloableから異なるスレッド上にあるレールにデータが別々に通知され、それぞれのレール上で受け取ったデータに値する処理を行い(mapメソッド)、sequentialメソッドでFlowableに戻すことで最終的に1つのSubscriberにデータが通知されていることがわかります。
まとめ
今回はRxJavaの非同期処理について見てきました。基本的にRxJavaの非同期処理はsubscribeOnメソッドやobserveOnメソッドを使ってどこを非同期処理させるのかがポイントになります。また、オペレータ内で生成されるFlowable/Observableが異なるスレッド上で実行される場合についても見てきました。加えて、RxJava 2.0.5から新たに追加されたParallelFlowableについても簡単に紹介しました。ただし、このParallelFlowabeはまだベータ版なので、今後APIや挙動などが変わっていく可能性がある、という点については注意してください。次回はこのPrallelFlowableについても少し詳しく見ていきます。